タブローで地方競馬のデータから競馬の格言を検証します。
part1は「人気薄の先行馬を買え」
さて、どういった結果になるのでしょうか!?
タブローで地方競馬のデータから競馬の格言を検証します。
part1は「人気薄の先行馬を買え」
さて、どういった結果になるのでしょうか!?
分散TensorFlowでロジスティック回帰 -Distributed TensorFlow- その1の続きです。
前回TensorFlowでシングル・ノード版のロジスティック回帰を実装し、MNISTの分類を行いました。
今回はロジスティック回帰を並列実行します。
並列実行環境として物理マシンを並べても良いのですが、お手軽にDockerコンテナを使います。
CentOS7にDockerを入れ、DockerHubからTensorFlowコンテナイメージを持ってきます。
TensorFlow0.8から並列分散処理がサポートされるようになりました。
大量のデータに対して高コストな計算を行う機械学習でも、たくさんマシンを並べれば数分〜数時間で終わらせることができるのは魅力ですよね。
どうやって分散するのか気になったので、これからやってみます。
最初のパートでロジスティック回帰のアルゴリズムをおさらいし、「分散しないTensorFlow」でロジスティック回帰を実装します。
次のパートで分散TensorFlowでロジスティック回帰による分類を行います。
使うのはTensorFlowお馴染みの、MNISTの数字手書き画像です。
Yogiboとはアメリカ発の「快適で動けなくなる」というキャッチコピーのソファー、クッションです。
こういう系のクッションは無印とかも出してますが、でかいのが欲しかったのでYogiboにたどり着きました。
先日インケンの家に導入してすごく快適になったのでご紹介します。
https://www.youtube.com/watch?v=rJp73cLkkJw
立てかけたり、座ったり、寝転んだりいろんな使い方ができます。
[続きをもっと見る…]
前回、Apache FlinkとはでFlinkの概要に触れたのですが、今回は実践的にkafkaと連携させ、Apache Zeppelinでアドホックに分析してみます。
Zeppelinを使うのは、単純に、jar作って実行するのが面倒だからです(^_-)-☆
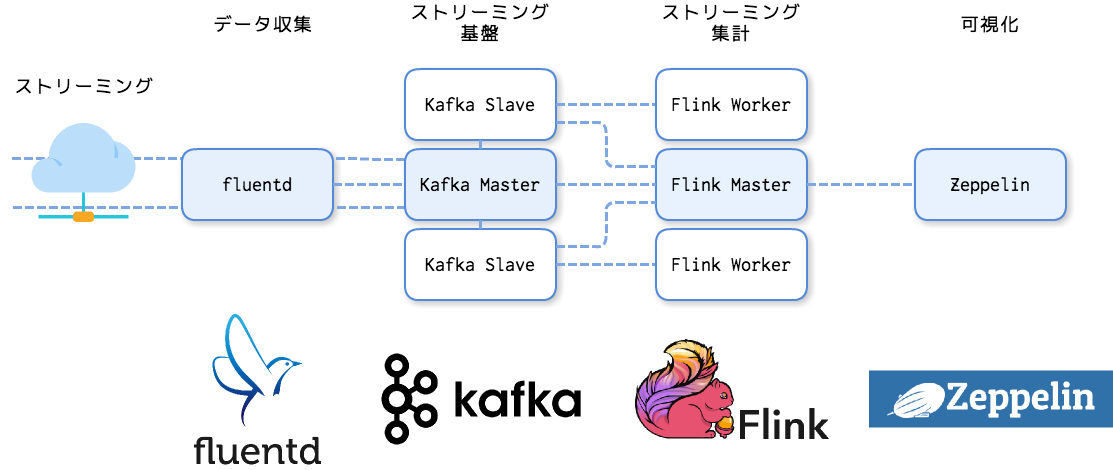
Flink2回めはkafkaとfluentdとの連携です。
と言っても、インスコするだけで終わっちゃいました。
なのでFlinkとの連携は次回