前回、Apache FlinkとはでFlinkの概要に触れたのですが、今回は実践的にkafkaと連携させ、Apache Zeppelinでアドホックに分析してみます。
Zeppelinを使うのは、単純に、jar作って実行するのが面倒だからです(^_-)-☆
概要
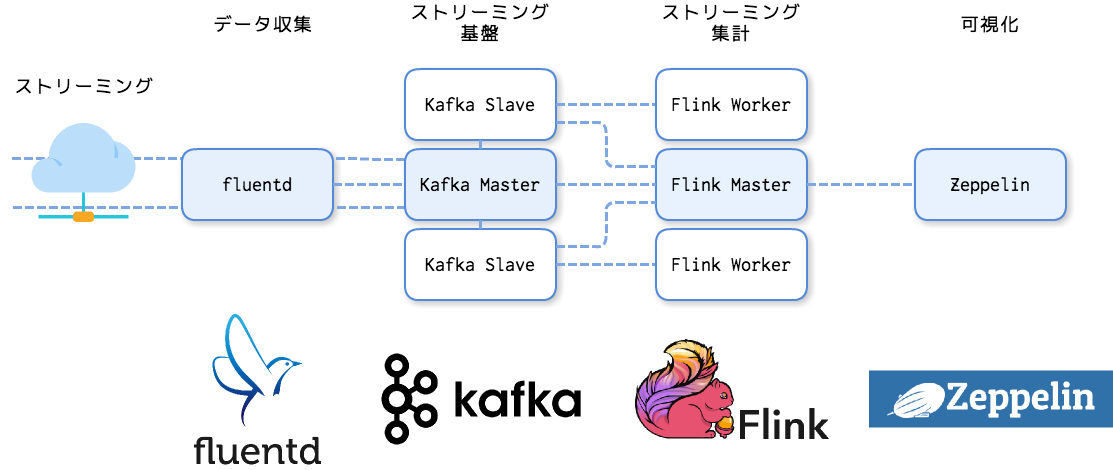
fluentdでデータを収集し、Kafkaにデータを送ります。
Zeppelin上のnotebookからflinkの集計ジョブを実行します。
flinkジョブはKafkaに集約されたストリーミング・データを集計します。
というわけでfluentd, Kafkaをインストールしていきます。
※ この記事ではCentOS 6.7 Finalを使います。またサーバ上ではrootで作業しています。
※ また、jdkはopenJDKの1.8を使用しています。
fluentd, Kafkaインストール
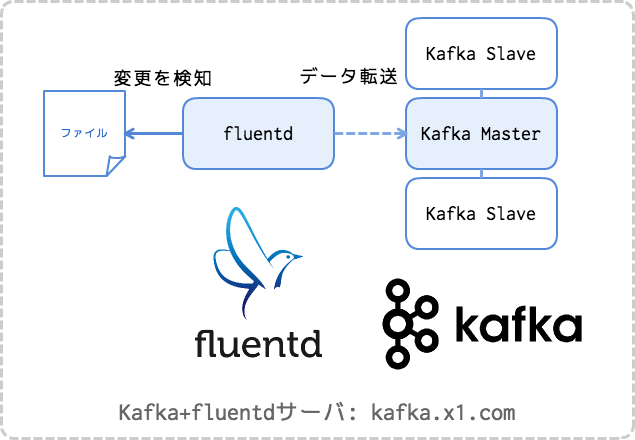
この記事ではfluentdとKafkaを1つのサーバの同居させて使います。
もちろん実際には別のノードにした方が良いケースが多くあるかと思います。
1. fluentd
まずはfluentdからですかね。
fluentdのインストール方法は公式ドキュメントに詳しく書かれています。
ここではRPMを使って td-agent をインストールしていきますが、まずは必須要件から。
ulimitを上げるためlimits.conf を編集します。
vi /etc/security/limits.conf ~ root soft nofile 65536 root hard nofile 65536 * soft nofile 65536 * hard nofile 65536 ~
ntpdがインストールされていない場合はntpdをインストールして起動設定をonにします。
yum -y install ntp
開発ツールをインストールします。
yum groupinstall 'Development tools'
終わったらマシンを再起動します。
あとは次のコマンドを実行するだけです。
curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent2.sh | sh
これでtd-agentがインストールされるので、kafkaプラグインを入れます。
td-agent-gem install fluent-plugin-kafka
2. Apache Kafka
Kafkaのインストールについては詳しい記事がたくさん存在するので、ここでは割愛します。
ここでは下記の記事どおりにkafkaを起動したこととして進めます。
Apache Kafka ―入門からTrifectaを用いた可視化まで―
※ 使用したkafkaのバージョンは kafka_2.11-0.9.0.1 です。
で、このKafkaサーバではzookeeperが2181, kafkaが9092ポートで待ち受けていることとします。
CLIなどを使ってKafka上にトピック stock_index を作っておきます。
KAFKA_HOME=/opt/kafka ZK="localhost:2181" $KAFKA_HOME/bin/kafka-topics.sh --create --topic stock_index --partitions 2 --zookeeper $ZK --replication-factor 1
これでfluentd→kafka連携の準備ができました。
3. fluentdからkafkaへ転送する
ある場所に置いたファイルにデータが追加されたらkafkaに送信するようfluentdの設定ファイルを編集します。
<source> type tail format json path /var/data/index.log pos_file /var/log/td-agent/index.log.pos time_format %Y-%m-%d %H:%M:%S time_key time keep_time_key true tag log.index </source> <match log.**> @type kafka time_format %Y-%m-%d %H:%M:%S time_field time brokers localhost:9092 zookeeper localhost:2181 default_topic stock_index output_data_type json required_acks 1 ack_timeout_ms 1500 </match>
td-agentを再起動します。
/etc/init.d/td-agent start
指定したファイルにデータを書き込むと、kafkaに転送されます。
echo '{"time":"2016-06-20 18:41:05","open":"1.14596","high":"1.14629","low":"1.14589","close":"1.14591","volume":"0","tag":"EURUSD"}' >> /var/data/index.log
これでfluentdとKafkaの準備はおわりです。
※ trifecta(インストールしていたら)や kafka-cli からメッセージ数が増えたことを確認することができます。
Flinkクラスタのインストール
Flinkクラスタの構築も公式ドキュメントの QuickStart に詳しく書いてあります。
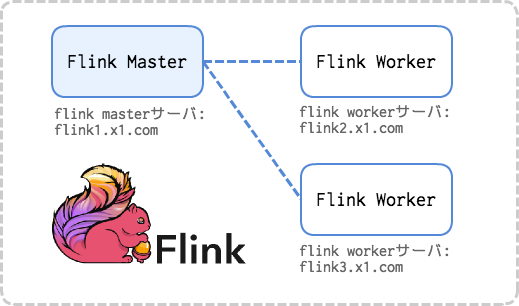
この記事では、公式ドキュメントと同じく、masterノード1台とworkerノード2台の合計3台構成でクラスタを構築します。
※ Flinkクラスタの構築は動画でも紹介しています。
Apache Flinkをインストール
1. JDKのインストール
JDK(>=1.7)をインストールします。
この記事ではopenJDKの1.8を使います。
yum -y install java-1.8.0-openjdk
2. Flinkバイナリの設置
FlinkのダウンロードページからHadoopとscalaのバージョンを選択してバイナリのダウンロード・リンクを取得し、全ノードでダウンロード→展開します。
cd /opt wget http://ftp.jaist.ac.jp/pub/apache/flink/flink-1.0.3/flink-1.0.3-bin-hadoop27-scala_2.11.tgz tar zxvf flink-1.0.3-bin-hadoop27-scala_2.11.tgz ln -nfs /opt/flink-1.0.3-bin-hadoop27-scala_2.11 /opt/flink
/optに解凍し、/opt/flinkというシンボリックリンクを張りました。
3. 設定ファイルの編集
master, workerの全てで conf/flink-conf.yaml の編集を行います。
| jobmanager.rpc.address | masterノードのアドレス(ホスト名でもよい)を指定 |
| taskmanager.heap.mb | workerノードで使用できるメモリ(MB)を指定 |
| taskmanager.numberOfTaskSlots | workerノードで使用できるCPU数を指定 |
| parallelism.default | ジョブの並列数。クラスタ全体で使用可能なCPU数 |
| taskmanager.tmp.dirs | workerノードのテンポラリ・ディレクトリ |
cp -pv /opt/flink/conf/flink-conf.yaml{,.bak}
vi /opt/flink/conf/flink-conf.yaml
~
jobmanager.rpc.port: 6123
jobmanager.heap.mb: 512
taskmanager.heap.mb: 1536
taskmanager.numberOfTaskSlots: 2
taskmanager.memory.preallocate: false
parallelism.default: 6
jobmanager.web.port: 8081
state.backend: jobmanager
taskmanager.tmp.dirs: /tmp
~
master, workerの全てで conf/slaves にworkerのアドレス(ホスト名でもよい)を列挙します。
cp -pv /opt/flink/conf/slaves{,.bak}
vi /opt/flink/conf/slaves
~
flink2.x1.com
flink3.x1.com
~
4. Flinkクラスタの起動
masterノードで起動スクリプトを実行します。
/opt/flink/bin/start-cluster.sh
以上でFlinkクラスタの構築は完了です。
Apache Zeppelinのインストール
最後に、Apache Zeppelinをインストールします。
Zeppelinのインストールは、公式ドキュメントよりもGitHubのREADMEを読んだ方が新しい情報が載っていて良いかと思います。
1. 必須要件のインストール
Zeppelinはフロント部分のビルドにnode.jsを使います。
yum -y install java-1.8.0-openjdk git npm fontconfig-devel
2. ソースコードのビルド
Zeppelinもバイナリはあるのですが、なかなか 0.6にバージョンが上がらないのでソースコードをビルドして使います。
cd /opt git clone https://github.com/apache/zeppelin.git ln -nfs /opt/incubator-zeppelin /opt/zeppelin cd /opt/zeppelin mvn install -Pspark-1.6 -Dspark.version=1.6.1 -Dhadoop.version=2.7.0 -Drat.numUnapprovedLicenses=100 -DskipTests -Ppyspark
Successが表示されたら完了です。
3. Zeppelinの起動
Zeppelinのデーモンを起動します。
cd /opt/zeppelin bin/zeppelin-daemon.sh start
ブラウザからZeppelinにアクセスします。
4. Flink接続設定を行う
Zeppelin のメニューから Interpreter をタップし、 Interpreter の設定ページヘ遷移します。
Flink の設定箇所があるので、
- hostにFlinkマスターのアドレス
- portにFlinkマスターの起動ポート
を設定します。
また、Kafkaと連携するためのjarを Dependencies に入力します。
| artifact | exclude |
| org.apache.flink:flink-connector-kafka-0.9_2.11:1.0.3 | |
| org.apache.flink:flink-streaming-scala_2.11:1.0.3 |
※ コネクタはkafkaのバージョンごとに異なります。このブログではkafka0.9.1+scala2.11を使っているので上記のjarを使いました。

Flinkカテゴリ右上の restart をタップして Interpreter の再起動を行います。
5. notebook からFlink へ接続
Zeppelinのnotebookを新規追加します。
Kafkaの設定をおこない、実行します。
ここまでで接続の確認は終了です。
ZeppelinからFlink を使って集計するサンプルは ZeppelinHub に公開されているので参考になります。
WordCount | ZeppelinHub viewer
次回、Zeppelinからkafkaに蓄積されたストリーミングデータを集計していきたいと思います。