ストリーミング処理に本気で取り組む必要があったので Apache Flink を使ってみました。
Apache Flinkとは?
分散ストリーミング処理エンジンです。
ストリーミングのみならずバッチ処理も行うことができますが、ストリーミングと静的データとを同じインターフェイスで扱うことができます。
- 分散システム
- 協調
- フォルト・トレランス
- データ・ストリーミングにおける分散環境
を提供すると謳っています。
本体はScalaで書かれていますが、java, scala, python* のAPIクライアントが用意されています。
クライアントは一連のオペレーションをデータフローとして記述します。
公式URL: http://flink.apache.org/
2016-03-08 メジャーバージョン(1.0.0) リリース。
2016-05-25 現在, 1.0.3。
Apache Flink のAPI
コアAPIといくつかのオプション的なAPIで構成されています。
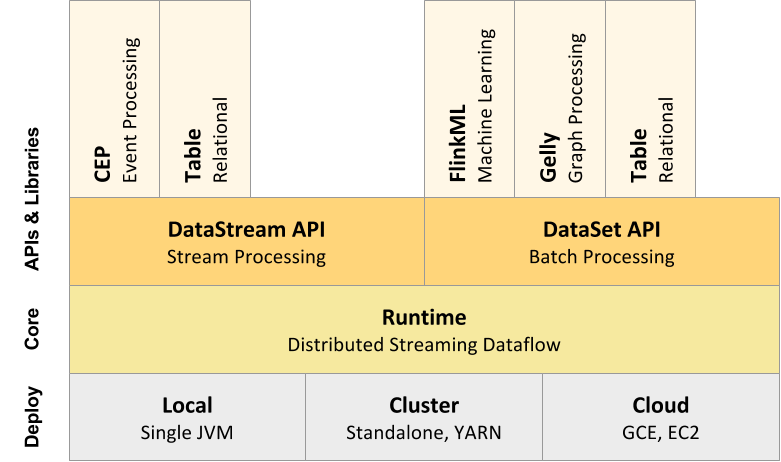
(https://ci.apache.org/projects/flink/flink-docs-release-1.0/ より)
コアAPI
- DataStream API ・・・ 無限ストリームを扱うAPI。Java, Scala。
- DataSet API ・・・ 静的データを扱うAPI。Java, Scala, Python。
- Table API ・・・ SQLを発行するAPI。Java, Scala。
オプション
- CEP ・・・ 複雑なイベント処理ライブラリ・API
- FlinkML ・・・ 機械学習ライブラリ・API
- Gelly ・・・ グラフ操作ライブラリ・API
構成がApache Sparkと似ています。
Apache Spark vs Flink
非常によく似たコンセプトのApache Spark(のストリーミング)とApache Flinkなので当然違いが気になります。
下記の米Yahooによるベンチマークや
https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at
CapitalOneのエンジニアの方が書かれた下記のスライドをみると違いが良くわかります。
(http://www.slideshare.net/sbaltagi/flink-vs-spark より)
ざっくり違いをまとめるとこんな感じです。
| # | Apache Spark | Apache Flink | 備考 |
|---|---|---|---|
| 処理方式 | micro batch | event driven | micro batchでは厳密なwindow集計が行えないケースがあります。 |
| throughputに対するレイテンシ | 線形増加 | 定数 | 米Yahooのベンチマーク参照 |
| 対応クライアント言語 | scala, java, python, R | scala, java, python | |
| REPL | ◯ | ☓ | |
| Web UI | 処理フローを表現するUIあり | ダッシュボード機能つきUIあり | |
| notebook Web UI | Apache Zeppelin, Jupyter, etc | Apache Zeppelin | ※ FlinkのJupyterから使えるのでは…? |
| YARN cluster | ◯ | ◯ |
この他に、Apache Flinkは
- ユーザ・コードによるOOMが発生しない
- GCを削減する
- 効率的なディスクI/O、ネットワーク転送
- ランタイム・チューニング不要
- 堅牢・安定パフォーマンス
といったアドバンテージがあるそうで、これを見て私は飛びつきましたw
(http://www.slideshare.net/sbaltagi/flink-vs-spark より)
次回、QuickStartに従ってApache Flinkをちょっと触ってみてからクラスタ構築をやってみます。
最終的には、fluentd → kafka → Flink → Apache Zeppelinでストリーミング集計 の流れを構築していきます。