分散TensorFlowでロジスティック回帰 -Distributed TensorFlow- その1の続きです。
前回TensorFlowでシングル・ノード版のロジスティック回帰を実装し、MNISTの分類を行いました。
今回はロジスティック回帰を並列実行します。
並列実行環境
並列実行環境として物理マシンを並べても良いのですが、お手軽にDockerコンテナを使います。
CentOS7にDockerを入れ、DockerHubからTensorFlowコンテナイメージを持ってきます。
yum -y install docker # dockerをサービスとして開始 systemctl start docker systemctl enable docker # DockerHubからtensorflowイメージをpull docker pull gcr.io/tensorflow/tensorflow
このイメージはTensorFlowのバージョンが低いので、Dockerfileを作成してTensorFlowをアップグレードします。
vi Dockerfile
~
FROM gcr.io/tensorflow/tensorflow
MAINTAINER x1 <viva008@gmail.com>
EXPOSE 8888 2222
# make directory -> mounted on host
RUN mkdir -p /var/data/shared
# upgrade pip
RUN pip install --upgrade pip
# upgrade tensorflow 0.8 to 0.9
ENV TF_BINARY_URL https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.9.0-cp27-none-linux_x86_64.whl
RUN pip -q uninstall -y tensorflow && \
pip -q install --ignore-installed --upgrade $TF_BINARY_URL
~
コンテナ間でチェック・ポイントを共有するための、共有マウント用ディレクトリ(/var/data/shared)の作成もこのDockerfileで行いました。
docker buildしてイメージの生成を行います。
docker build -t tensorflow:0.9.0 .
TensorFlowの分散処理には下記のロールが必要になります。
- パラメータの計算を並列化するパラメータ・サーバ
- 勾配・損失計算を並列化するワーカー・ホスト
並列化の様子を観察するため、パラメータ・サーバ2台とワーカー・ホスト2台を起動します。
# パラメータ・サーバ1 ps_93 docker run --privileged -td -p 3223:3223 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name ps_93 tensorflow:0.9.0 # tensorflow.x1.com はDockerホストのホスト名、172.xx.xx.xxはDockerホストのIPです。 # 各ホストに割り当てるポートを開放しておきます。 # ホストの/var/data/sharedにコンテナの/var/data/sharedをマウントします。 # パラメータ・サーバ2 ps_94 docker run --privileged -td -p 3224:3224 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name ps_94 tensorflow:0.9.0 # ワーカー・ホスト1 wk_93 docker run --privileged -td -p 2223:2223 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name wk_93 tensorflow:0.9.0 # ワーカー・ホスト3 wk_94 docker run --privileged -td -p 2224:2224 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name wk_94 tensorflow:0.9.0
並列実行版ソースコード
公式のDistributed TensorFlow r0.9にはグラフ間レプリケーション・非同期訓練のスケルトンが掲載されているのですが、面倒な勾配の集約をフレームワークに任せたかったのでグラフ間レプリケーション・同期訓練で作成しました。
LogisticRegression.py
#!/usr/bin/env python
#-*- encoding: utf-8 -*-
# vim: tabstop=8 expandtab shiftwidth=4 softtabstop=4
from __future__ import print_function
import tensorflow as tf
import sys
import time
from tensorflow.examples.tutorials.mnist import input_data
# Flags for defining the tf.train.ClusterSpec
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Flags for defining the tf.train.Server
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
# config
batch_size = 100
learning_rate = 0.001
training_epochs = 10
# ホスト間で共有可能なディレクトリを指定します。
board_path = "/var/data/shared/board"
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
worker_num = len(worker_hosts)
# cluster を作成します。
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# ローカル・タスクを実行するサーバを開始します。
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
is_chief = (FLAGS.task_index == 0)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# 更新数のカウンター
global_step = tf.get_variable('global_step', [],
initializer = tf.constant_initializer(0),
trainable = False)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, shape=[None, 784], name="x-input") # mnist data image of shape 28*28=784
y_ = tf.placeholder(tf.float32, shape=[None, 10], name="y-input") # 0〜9 10 classes
with tf.name_scope("weights"):
W = tf.Variable(tf.zeros([784, 10]))
with tf.name_scope("biases"):
b = tf.Variable(tf.zeros([10]))
with tf.name_scope("softmax"):
y = tf.nn.softmax(tf.matmul(x, W) + b)
with tf.name_scope('cross_entropy'):
#cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
# optimizer
with tf.name_scope('train'):
grad_op = tf.train.GradientDescentOptimizer(learning_rate)
# SyncReplicasOptimizerを使うと、同期的に勾配を集約してオプティマイザに渡すことができます。
rep_op = tf.train.SyncReplicasOptimizer(grad_op,
replicas_to_aggregate=worker_num,
replica_id=FLAGS.task_index,
total_num_replicas=worker_num,
use_locking=True)
train_op = rep_op.minimize(cross_entropy, global_step=global_step)
#train_op = grad_op.minimize(cross_entropy, global_step=global_step)
init_token_op = rep_op.get_init_tokens_op()
chief_queue_runner = rep_op.get_chief_queue_runner()
with tf.name_scope('Accuracy'):
# accuracy
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.scalar_summary("cost", cross_entropy)
tf.scalar_summary("accuracy", accuracy)
#saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
print("Variables initialized ...")
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
global_step=global_step,
init_op=init_op)
begin_time = time.time()
frequency = 100
with sv.prepare_or_wait_for_session(server.target, config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
# is chief
if is_chief:
sv.start_queue_runners(sess, [chief_queue_runner])
sess.run(init_token_op)
writer = tf.train.SummaryWriter(board_path, graph=tf.get_default_graph())
start_time = time.time()
for epoch in range(training_epochs):
batch_count = int(mnist.train.num_examples/batch_size)
count = 0
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
if i % worker_num == FLAGS.task_index:
continue
_, cost, summary, step = sess.run(
[train_op, cross_entropy, summary_op, global_step],
feed_dict={x: batch_x, y_: batch_y})
writer.add_summary(summary, step)
count += 1
if count % frequency == 0 or i+1 == batch_count:
elapsed_time = time.time() - start_time
start_time = time.time()
print("Step: %d," % (step+1),
" Epoch: %2d," % (epoch+1),
" Batch: %3d of %3d," % (i+1, batch_count),
" Cost: %.4f," % cost,
" AvgTime: %3.2fms" % float(elapsed_time*1000/frequency))
count = 0
print("Test-Accuracy: %2.2f" % sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
print("Total Time: %3.2fs" % float(time.time() - begin_time))
print("Final Cost: %.4f" % cost)
#sv.stop()
if is_chief:
sv.request_stop()
else:
sv.stop()
print("done")
if __name__ == "__main__":
tf.app.run()
このソースコードはDISTRIBUTED TENSORFLOW EXAMPLEを大変参考にさせて頂きました。
実行
dockerコンテナに入り上記のLogisticRegression.pyを実行します。
パラメータ・サーバから起動します。
docker exec -it ps_93 /bin/bash root@2acc72e5e58b: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name=ps --task_index=0 docker exec -it ps_94 /bin/bash root@08e6eb86c897: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name=ps --task_index=1
ワーカー・ホストはマスターノードから起動します。
docker exec -it wk_93 /bin/bash root@a5e04c49edec: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name=worker --task_index=0 docker exec -it wk_94 /bin/bash root@bde152d25ffd: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name= worker --task_index=1
結果
実行結果です。epoch=10で実行しました。
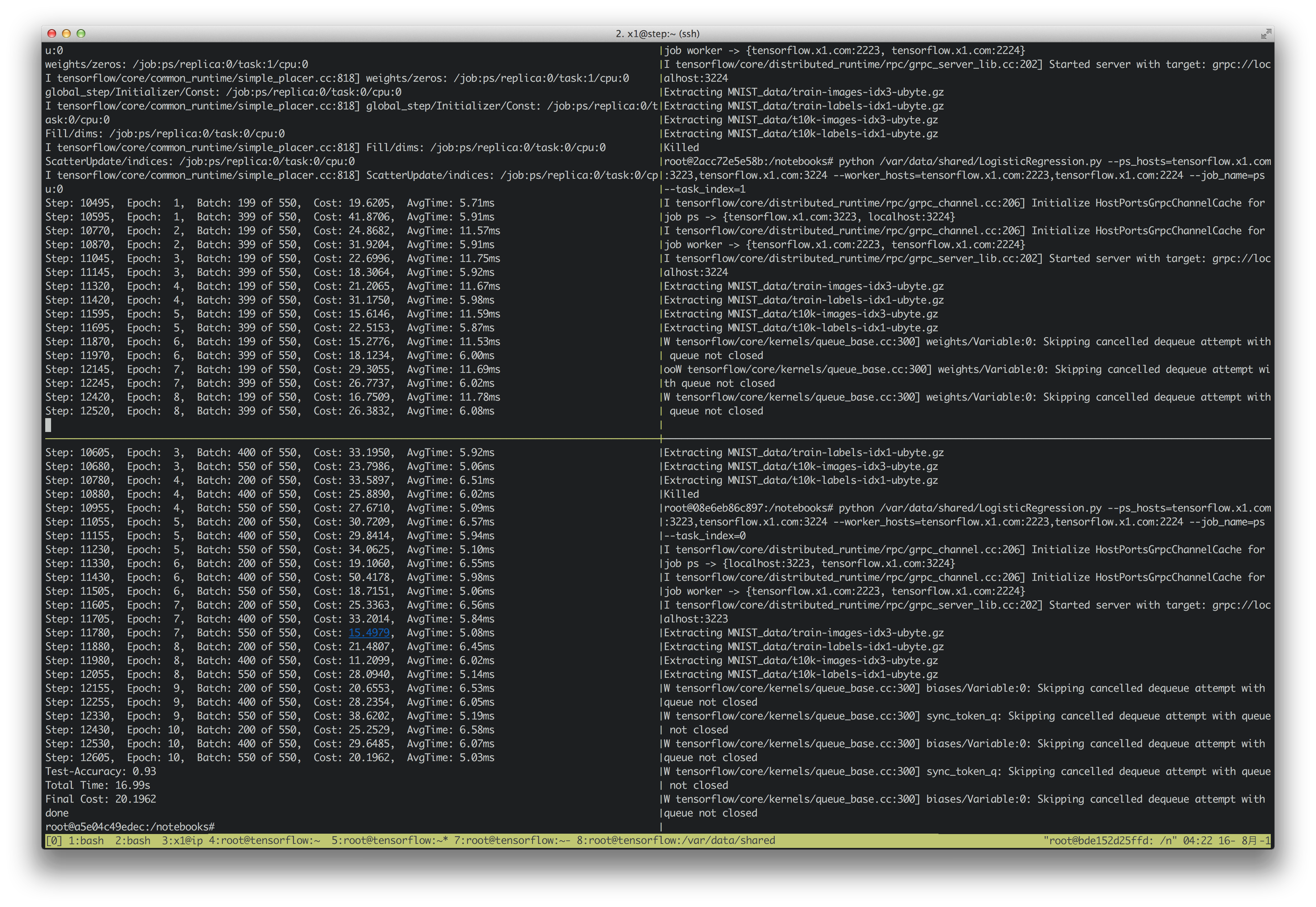
Test-Accuracy: 0.92 Total Time: 25.24s Final Cost: 47.4627
シングルノード版よりも少し精度が良いという以外な結果に…?
各ノードのtopの様子です。
すべてのCPUが使われているのがわかります。

ソースコードはこちらです。
DistributedTensorFlow.ipynb