Scala Matsuri 2016でお話させて頂いた「あなたのScalaを爆速にする7つの方法」の日本語版です。
発表の時に使った英語版はこちらです。
Scala Matsuri 2016でお話させて頂いた「あなたのScalaを爆速にする7つの方法」の日本語版です。
発表の時に使った英語版はこちらです。
Druid 4回目はpanoramixを使って、wikipediaのデータ可視化を行います。
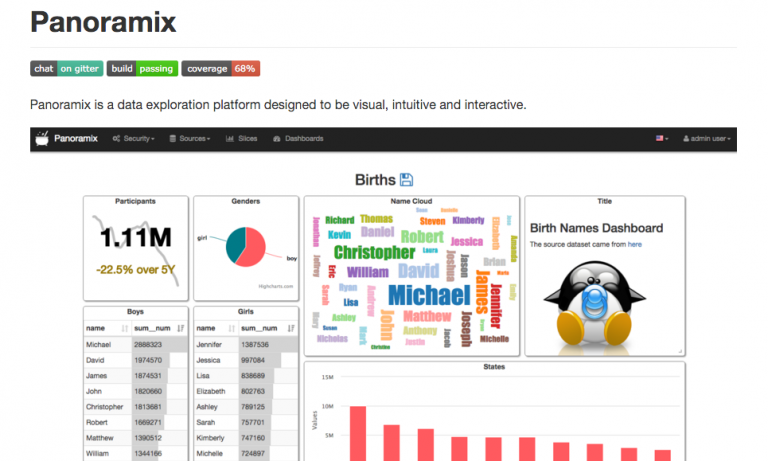
panoramixはdruid part2でやったpivotみたいなソフトなのですが、pivotよりいろいろできるみたいなのでもしかしたらdruidのBIツールのデファクトになるかもしれませんね。
実はpanoramixはpart3のclusterより先に撮っていたのですが、どうにもこうにもdruidとつながらなくて、druid clusterが必要とわかったため、急遽part3にdruid clusterを差し込んだという経緯があります。
まだ発展途上のpanoramixは情報がネットにもほとんど載っていなくて導入には苦労しますが、良さ気なツールなので今後に期待です。
SparkSQLリファレンス第三部、関数編です。
宜しければ
Apache Spark: SparkSQLリファレンス〜構文編〜
Apache Spark: SparkSQLリファレンス〜演算子編〜
もご覧ください。
SparkSQLリファレンス第四部、関数編のラストその他の関数です。
SparkSQLには便利なユーティリティ関数がたくさんあります。
今回はそれをご紹介していきたいと思います。

ブラウザの表示確認てめんどくさいですよね。
そこでseleniumです。
seleniumはUIテストツールですね。簡単にブラウザのスクリーンショットを撮れるので、表示確認を自動化しちゃいましょう。
今回はchrome firefox safari iphone androidのキャプチャを自動で撮りたいと思います。
iphone androidはchromeのdeveloperツールのエミュレート機能を使ってキャプチャします。
IEは未対応です。MacなのでIE撮るのはめんどくさそう。
まずは、seleniumのダウンロードページから、以下をダウンロードしてきます。
・Selenium Standalone Server
・SafariDriver
・Google Chrome Driver
Druid part2はpivotを使ってデータを可視化していきます。
pivotのインストール
npm i -g imply-pivot
pivotにはサンプルが入ってるので、それを動かしてみます。
pivot --example wiki