ajaxなページもクローラーに読ませたいですよね。
そこでPhantomJS, CasperJS, SpookyJSです。
簡単に説明するとこんな感じ
PhantomJS
コマンドラインから使える画面がないwebkitブラウザ
CasperJS
PhantomJSのユーティリティ、PhantomJSをもっと便利に使えるようにするやつ
SpookyJS
casperJSをNodejsから使えるようにするやつ
Elasticsearchの日本語の形態素解析は基本的にkuromojiを使うのですが、けっこうよく出来てて「え?これまで拾っちゃう?」って思うこともしばしば。
かすってそうなデータも拾ってくれるのはありがたいのですが、さすがにノイズだらけって場合もあるので、スコアでフィルタリングしたいと思います。
ついでにPHPでの検索の投げ方も。
前回に引き続きPython初心者シリーズ
みずほのサイトからロト7の当選番号をすっぱ抜いてくるサンプルを紹介します。
PHPでスクレイピングをやろうとすると、curlで取ったHTMLをpreg_match等を使ってDOMを解析することになりますよね(今はもっと便利なモジュールがあるのかもしれないけど)
Pythonだと、BeautifulSoupという大変便利なモジュールがあります。
パースされたデータに対しての操作が超絶便利です。
バツイチちゃんがSolrのこと書いてたので、インケンはElasticsearchのこと書きます。
xmlよりjson派なインケンとしてはsolrなんかより、elasticsearch押しです。solr使ったことないけどね!
elasticsearchはRESTリクエスト飛ばせば、検索登録更新削除すべて行うことができるのですが、RabbitMQのプラグインを使うと、登録更新削除をキューにメッセージ投げるだけでいいので、大変便利です。
MQにメッセージ投げる際には、elasticsearchのbulk api形式で送る必要があります。
その辺がわかりづらかったので、サンプル交えてご紹介します。
あけましておめでとうございます。バツイチです。
年が明けて2014年になりました。
2013年を振りかえるとデータサイエンスと関数型言語の流行が目立ったように感じます。
2014年はそろそろ圏論が流行るのではないかと思っています。
(型システム入門がAmazonの技術書売上数ランキング100位以内に入ったことですし)
定理証明系言語Coqも台頭してくるかもしれません。
Solr4を動かしてみるシリーズの5回目です。
今回はSolr4でmaster-slaveの単純レプリケーションを構築したいと思います。
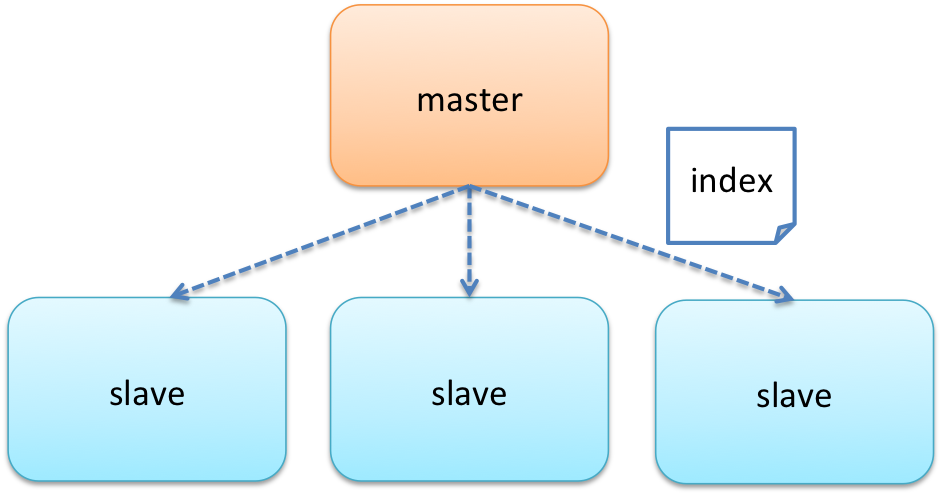
レプリケーションの構成にはReplicationHandlerを使います。
coreのインスタンスディレクトリ下のconf内にあるsolrconfig.xmlを開くと、レプリケーション構成のテンプレートが記述してあり、この部分のコメントを外して必要な項目を設定すればレプリケーション完了なのです(`_´)ゞ
Pythonまったく使ったことないから、Pythonでなんか作ってみようと思ったのがきっかけです。
かといって、「Hello World」出すだけなんてしょーもないことしても意味が無いので、ちゃんとフレームワークを使ってMVCっぽく作ろうと思いました。
せっかくなので、自分がマンガを今何巻まで持っているかを管理するツールを作りたいと思います。いつも何巻まで持ってたっけかなーって忘れちゃうので。
CRUDの基本を抑えたサンプルです。
ちなみに、Pythonの構文やモジュールのインストール等は、検索すればすぐ出てくるのでググってください。