Rust の Web Framework、 actix_web は TechEmpower のベンチマークでは、すごいパフォーマンスを示しています。
しかし、業務で使おうと思ったときに、本当のところどうなの?というのは気になるところです。
特に私の所属するアドテク界隈では、ミリ秒単位のパフォーマンス・チューニングが求められます。
実際、当初actix_webで要求レイテンシを満たせませんでした。
しかし、同僚の非常に有用なアドバイスにより打開することができたため、ブログにて公開しようと思った次第です。
パフォーマンスの測定及びチューニングは、下記のケースで行いました。
- 固定文字列を返すだけ
- 100msスリープしてから固定文字列を返す
- 外部サーバにgRPC通信し結果を返す
※ 実は上記以外のケースでもベンチマークを取っております。結果とソースコードはGithubにて公開しました。
https://github.com/x1-/actix_web_benchmark
結果だけ知りたい方はこちらをご覧になられた方が良いかもしれません。
2018.11.01 追記
actix_web は HTTPコネクションが正しく閉じない問題が未だ解決しておりません(TT)
Connection not closed correctly #439
昨日(10/31)、 @legokichi さんから TCP FIN が正しくされていないのでは?とご指摘が入っています。
前提条件
サーバ・スペックは下記の通りです。
actix-web サーバのスペック
| 環境 | GCP |
|---|---|
| インスタンス | n1-standard-4 × 1台 |
| vCPU | 4 cores |
| メモリ | 15 GB |
| OS | Ubuntu16.4 |
負荷サーバのスペック
| 環境 | GCP |
|---|---|
| インスタンス | n1-standard-2 × 4台 |
| vCPU | 2 cores |
| メモリ | 7.5 GB |
| OS | Ubuntu16.4 |
| 負荷ツール | tsung |
Erlang製のtsungというツールを使って負荷をかけました。
これは、複数のサーバをクラスタ化して負荷をかけることができるので、負荷側が先にパンクするケースを軽減できます。
パフォーマンス測定の前に
actix_web 関係なく、 もはや Webサーバの基本と言っても良いのですが、actix_webを動作させるサーバと負荷サーバの両方で、 ulimit(システムリソース上限) と tcp系のカーネル・パラメータを調整します。
ulimit
システムリソース上限を上限いっぱいに設定します。
/etc/security/limits.conf を編集します。
root soft nofile 65536 root hard nofile 65536 * soft nofile 65536 * hard nofile 65536
再起動します。
カーネル・パラメータ
いくつかのカーネル・パラメータをいじります。
/etc/sysctl.conf を編集します。
kernel.pid_max=65536 net.core.somaxconn=65535 net.core.netdev_max_backlog = 8192 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_wmem = 4096 12582912 16777216 net.ipv4.tcp_rmem = 4096 12582912 16777216 net.ipv4.tcp_max_syn_backlog = 8192 net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_tw_reuse = 1 net.ipv4.ip_local_port_range="1024 65535" net.ipv4.tcp_orphan_retries = 3 net.ipv4.tcp_abort_on_overflow=1 net.ipv4.tcp_sack = 1 net.ipv4.tcp_fack = 1 net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.netfilter.nf_conntrack_max=65536 vm.swappiness = 0
sysctl -p で反映させます。
カーネル・パラメータに関しましては、こちらのサイトを大変参考にさせて頂きましたm(_ _;)m
- nginx – カーネルパラメーターのチューニング
- 以前会社で使っていたsysctlとさらに改良
- Linux Web Server Performance Benchmark – 2016 Results
では、負荷をかけていきます。
1. 固定文字列を返すだけ
まずは、GETリクエストに対して固定文字列レスポンスを返すだけの、最もシンプルなエンドポイントのパフォーマンスを測定してみました。
ソースコードは下記の通りです。
公式の Gettings Started とほぼ同じです。
※ 全てのソースコードは cargoでreleaseビルドしています。
( cargo run –release -j 2 )
extern crate actix;
extern crate actix_web;
#[macro_use]
extern crate log;
use actix::prelude::*;
use actix_web::{error, server, App, AsyncResponder, FutureResponse, HttpRequest, HttpResponse};
use actix_web::http::Method;
use actix_web::middleware::{Logger as ActixLogger};
fn main() {
let sys = actix::System::new("BenchServer");
server::HttpServer::new(move || {
vec![
App::new()
.middleware(ActixLogger::default())
.resource("/health",|r| r.method(Method::GET).f(health))
]
})
.backlog(256) // コネクションを獲得できなかったクライアントの待ち行列数です.
.keep_alive(server::KeepAlive::Timeout(0))
.shutdown_timeout(60)
.workers(128) // 起動スレッド数です.
.bind("0.0.0.0:8080")
.unwrap()
.start();
let _ = sys.run();
}
fn health(_: &HttpRequest) -> &'static str { "ok" }
主に、 backlog の値と workers の値を変動させてチューニングを行います。
実験. 1.1
actix_web のパラメータ
– backlog: 256
– worker: 128
結果
| 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|
| 1,000 | 0.430 | 938.08 | |
| 5,000 | 0.444 | 4637.53 | |
| 10,000 | 0.804 | 8368.71 | |
| 12,000 | 1.40 | 9276.77 | |
| 14,000 | 25.14 | 10107.44 | |
| 15,000 | 30.77 | 9947.43 | rpsが14,000から上がらない |
12,000 req/secが限界と考えて良いでしょう。
backlog: 256 , worker: 128 の弱気設定でも、固定文字列を返すだけなら 10,000 rps 以上捌けてしまいます。
2. 100msスリープしてから固定文字列を返す
次の実験は、固定文字列を返す前に100msのスリープを入れます。
ソースコードには下記を追加しました。
use std::{thread, time};
:
App::new()
.middleware(ActixLogger::default())
.resource("/health",|r| r.method(Method::GET).f(health))
.resource("/sleep", |r| r.method(Method::GET).f(sleep))
:
fn sleep(_: &HttpRequest) -> &'static str {
thread::sleep(time::Duration::from_millis(100));
"done"
}
実験. 2.1
actix_web のパラメータ
– backlog: 256
– worker: 128
結果
| 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|
| 1,000 | 100 | 932.47 | 100msの理論値 |
| 2,000 | 5,740 | 951.62 | 話にならない |
2,000 req/sec の負荷をかけると、パフォーマンスだだ下がりです。
100ms のスリープと文字列を返すだけで、 5秒以上かかってはたまりません 💦
グラフを見ると、線形にレスポンスタイムが増加しています。

実験. 2.2
次に、 backlog のみ増やしてみます。
actix_web のパラメータ
– backlog: 2,048
– worker: 128
結果
| 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|
| 1,200 | 100 | 1119.26 | 100msの理論値 |
| 2,000 | 5,600 | 943.93 | 耐えきれないときの劣化が激しい |
相変わらず 2,000 req/sec の負荷には耐えられません。
actix_web…この程度の実力なんでしょうか😰
実験. 2.3
次は、 backlog を 0 にし、worker を増やしてみます。
actix_web のパラメータ
– backlog: 0
– worker: 1,024
結果
| 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|
| 2,000 | 100 | 1881.76 | 余裕になった |
| 10,000 | 110 | 8468.29 | まだいけそう |
| 15,000 | 1,040 | 4173.83 | 10,000req/sec の半分くらいしか捌けていない |
突如、 2,000 req/sec を捌けるようになりました。
要はスレッド数が全然足りていなかった、ということですね💦
しかし、 10,000 req/sec と 15,000 req/sec の間に壁がありそうです。
性能が 10,000 – 15,000 req/sec なのは、まあ良いとしても、突然遅くなるのは困ります。
だったらコネクション切ってエラーにしてくれた方が良いです。
と、ここまで負荷テストをやってみて、バックプレッシャーをうまく捌けていないんじゃ?と思いました。
調べてみると、 issue が上がっていました。
修正コミットが actix_web 0.7.4 には取り込まれているようです。ほっ☺
このコミットを追っていくと、 backlog 設定は 、 TCPリスナーの Listen数 として使われています。
https://github.com/actix/actix-web/blob/8c89c90c50f64bb411db1a95aeec6b2a1cc9d9e1/src/server/srv.rs#L779
backlog = 0 なんて、論外でした… 😨
これを見ると、 backlog も worker も OS の限界まで上げれば、OS限界性能まで出せそうです(理論的には)。
実験. 2.4
というわけで次は、 backlog も worker もゴソッと上げて負荷をかけてみます。
actix_web のパラメータ
– backlog: 1,024 or 7,168 (OSのbacklog は 8,192)
– worker: 4,096 or 8,096 (OSのMaxスレッド数は12万くらい)
結果
| backlog | worker | 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|---|---|
| 1,024 | 4,096 | 15,000 | 640 | 6717.64 | 桁は上がったけれど、まだきつそう |
| 7,168 | 4,096 | 15,000 | 550 | 10023.54 | low は 100ms なので許容してよさそう |
| 7,168 | 8,096 | 15,000 | 590 | 10021.28 | worker=4,096と大差なし |
15,000 req/seq 負荷時のパフォーマンスが相当向上しました。
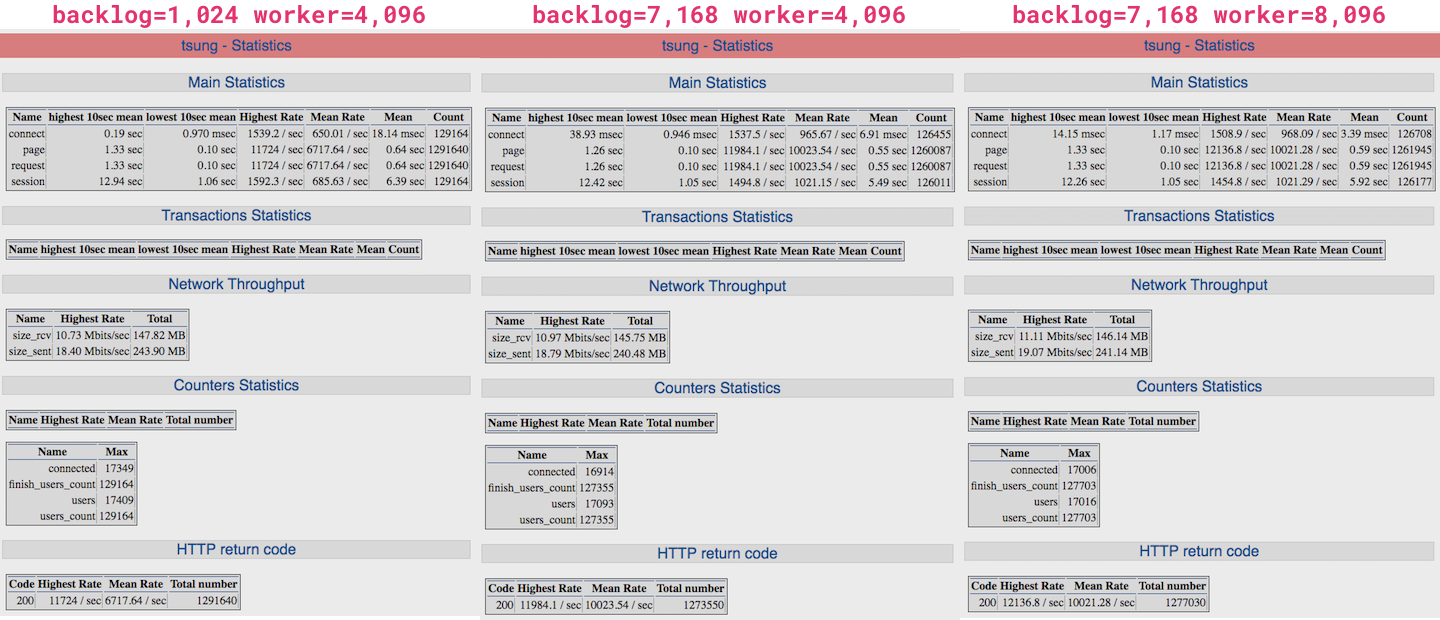
n1-standard-4 1台で 15,000 rps 捌けるとしたら許容範囲としたいところです。
3. 外部サーバにgRPC通信し結果を返す
最後に、外部サーバにgRPC通信し結果を返すエンドポイントのパフォーマンスを測定します。
この外部サーバのレスポンスタイムは 数ms〜数百ms です。
これは、処理時間が外部APIに依存するケースを測定するのが目的でした。
ソースコードには下記を追加しました。
extern crate grpc;
pub mod hello;
pub mod hello_grpc;
use std::sync::Arc;
use grpc;
use hello::*;
use hello_grpc::*;
struct ApplicationState {
grpc_client : HelloServiceClient,
}
fn main() {
let mut client_conf = grpc::ClientConf::new();
client_conf.http.connection_timeout = Some(Duration::from_millis(200));
let client = HelloServiceClient::new_plain("xxx.xxx.xxx.xxx", 50051, client_conf).unwrap();
let state = Arc::new(ApplicationState {
grpc_client : client,
});
App::with_state(state.clone())
.middleware(ActixLogger::default())
.resource("/health", |r| r.method(Method::GET).f(health))
.resource("/sleep", |r| r.method(Method::GET).f(sleep))
.resource("/grpc_wait", |r| r.method(Method::GET).f(Server::grpc_wait)) // 1つのgRPCクライアントを参照して使います
.resource("/grpc_per", |r| r.method(Method::GET).f(Server::grpc_per)) // gRPCクライアントをリクエスト毎に生成します
:
///
/// 1つのgRPCクライアントを参照して使います
///
fn grpc_wait(req: &HttpRequest<Arc<ApplicationState>>) -> String {
let mut v = HelloRequest::new();
v.set_id(String::from("000001"));
v.set_message(String::from("rustcean loves rust"));
let resp = req.state().grpc_client.say(grpc::RequestOptions::new(), v);
format!("grpc: {:?}", resp.wait())
}
///
/// gRPCクライアントをリクエスト毎に生成します
///
fn grpc_per(_: &HttpRequest<Arc<ApplicationState>>) -> String {
let mut client_conf = grpc::ClientConf::new();
client_conf.http.connection_timeout = Some(Duration::from_millis(200));
let client = HelloServiceClient::new_plain("xxx.xxx.xxx.xxx", 50001, client_conf).unwrap();
let mut v = HelloRequest::new();
v.set_id(String::from("000001"));
v.set_message(String::from("rustcean loves rust"));
let resp = client.say(grpc::RequestOptions::new(), v);
format!("grpc: {:?}", resp.wait())
}
実験. 3.1
gRPC クライアント を actix_web のステートに保存しておいて、各スレッドで保存したクライアントの参照を使って gRPC 通信を行います。
actix_web のパラメータ
– backlog: 7,168
– worker: 8,192
結果
| 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|
| 200 | 10.44 | 188.99 | |
| 400 | 17.72 | 371.38 | |
| 600 | 58.16 | 559.45 | |
| 700 | 490.00 | 651.23 |
スリープ100msのケースで 10,000 rps 捌いていたことを考えると、 600 rps が限界というのは少なすぎです…
700 req/sec のグラフを見ると、安定して 500ms/req 前後 かかるのが気になります…
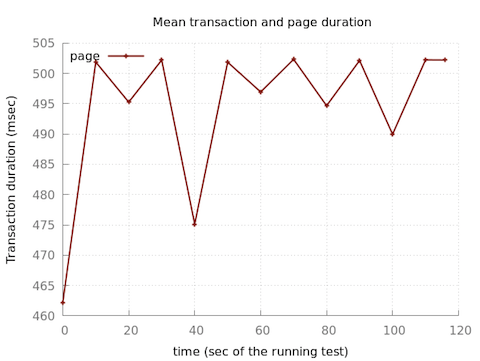
まさかこれ・・・?
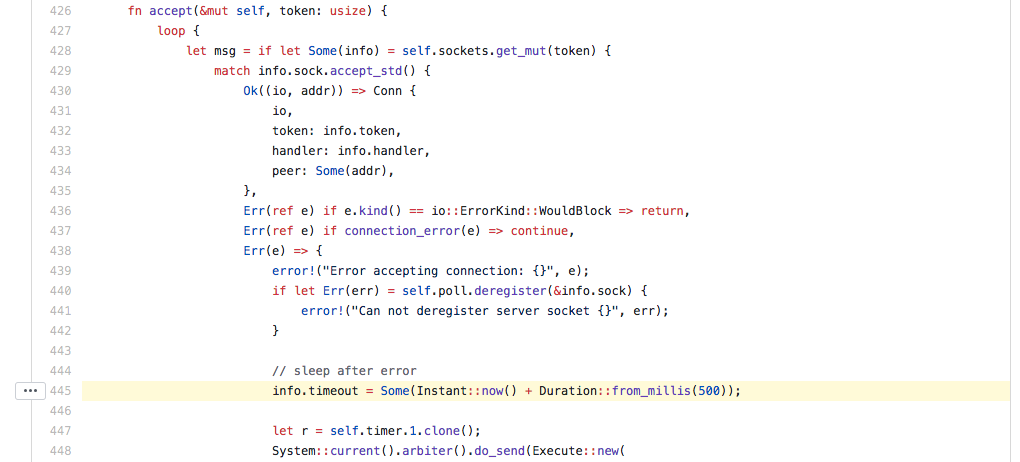
エラーの後に Sleep(500ms) しています😰
actix_web の実装では、コネクションが獲得できなかった場合に、接続を得ようとしているクライアントを 500ms スリープさせるようです、、、
actix_web に設定した worker数は 8192 で、 worker毎の最大コネクション数は 100k なので、設定上はコネクション数十分なはずです(フルに使ったらOSがハングアップしますが)。
https://actix.rs/actix-web/actix_web/server/struct.HttpServer.html#method.maxconn
ということは、 もう1つの通信であるgRPCクライアントがtcpコネクションを使い回さず、開放もせず溜め続けているのでは・・・?と疑ってしまいます。
実験. 3.2
gRPC クライアントをリクエスト毎に生成して gRPC 通信を行います(一見非効率な感じがしますが)。
Rustの特性的には、これでリクエストごとにクライアントを生成すれば、クライアントが確保したコネクションも開放されるはずです。
actix_web のパラメータ
– backlog: 7,168
– worker: 8,192
結果
| 送信req/sec | speed(ms) | rps | 備考 |
|---|---|---|---|
| 200 | 9.43 | 174.28 | |
| 400 | 7.02 | 335.26 | |
| 600 | 9.49 | 516.24 | |
| 800 | 18.12 | 661.33 | |
| 1,000 | 33.43 | 750.70 | |
| 1,200 | 62.10 | 817.64 | |
| 1,300 | – | – | クラッシュ |
1,300 rps の途中で panic してしまいました 😅
が、パフォーマンスは2倍向上しました。
1,300 rpsではOS限界までtcpコネクションを使ってくれたかと思います。
※ 今回は gRPC通信という形で外部通信を行いましたが、 DBにつないだり、REST APIを叩いたりも全てtcpコネクションを使うので、コネクション数の設定はよく考慮する必要があります。
まとめ
- まずはカーネル
・パラメータのチューニング(これやらないとフレームワークの本当の実力がわからない) - actix_web は backpressure対応が入った 0.7.4 以降を使いましょう
- 有限資源のtcpコネクションの見積もり大事
ここで紹介させて頂いた、ソースコードは Github にて公開しております。
宜しければご覧くださいませ。
https://github.com/x1-/actix_web_benchmark