![]()
implyにはDruidのBIツールのpivotが入っているのですが、機能が少ない上に確か一定期間後に有料だった気がするので、オープンソースのSupersetを入れることにします。
このsupersetは以前書いた記事で、panoramixという名前で開発されていましたが、supersetという名前になりAirbnbのもとで開発が進められるようになったみたいです。
panoramixの時もいろんなグラフが生成できましたが、supersetでは更にパワーアップしています。
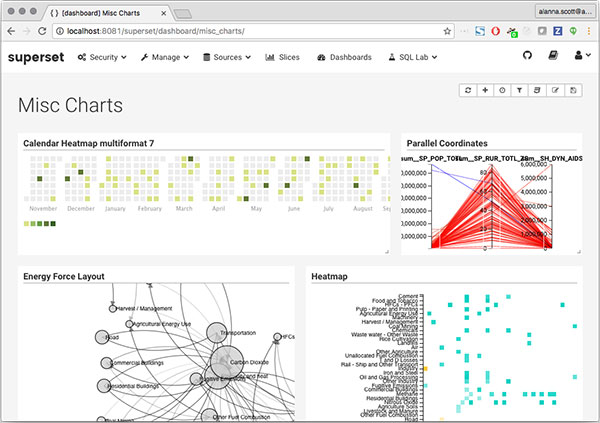
もちろんデータソースはDruidだけではなく、各RDBとも接続できます。
インストール
supersetはpython製なのでpipでサクッと入るのですが、python2.7、python3.4以上なので2.6だと動きません
インストールはドキュメントどおりにやっていけば大丈夫ですが、途中で必要なライブラリが色々出てきたりするので環境によっては若干つまづくかも。
ドキュメントではvirtualenvで入れてますが、自分はanacondaの2.7を入れました。
あとこの辺も自分の環境では必要でした。
yum install gcc-c++ cyrus-sasl-devel openssl-devel
Druidとつなぐ
druidと繋ぐ前に、druid側でDatasourceの設定が必要です。前回のimplyの設定の項目でやった、conf-quickstart/tranquility/kafka.json のことですね。
さて、supersetインストール時に設定した管理者アカウントでsupersetにアクセスします。
そして上部タブのSourcesのDruid Clustersにアクセスし、Druid Clusterを設定します。これはDruidを1台のマシンで動かしてても必要です。
Druid Clusterを+ボタンを押して追加します。

今回サーバーが1台だけで試してるので、Coodinator Brokerがlocahostですが、他のサーバーで動いている場合はHostのIPを指定します。
クラスターを作成したら、上部タブのSourcesのRefresh Druid Metadataをクリックすると、自動でDruidの設定ファイルからDatasourceが読み込まれます。
Datasourceが作成されたら、まず編集します。
Druidでは基本的に時間をUTCで管理してるので、Time Offsetに日本時間の9を設定します。
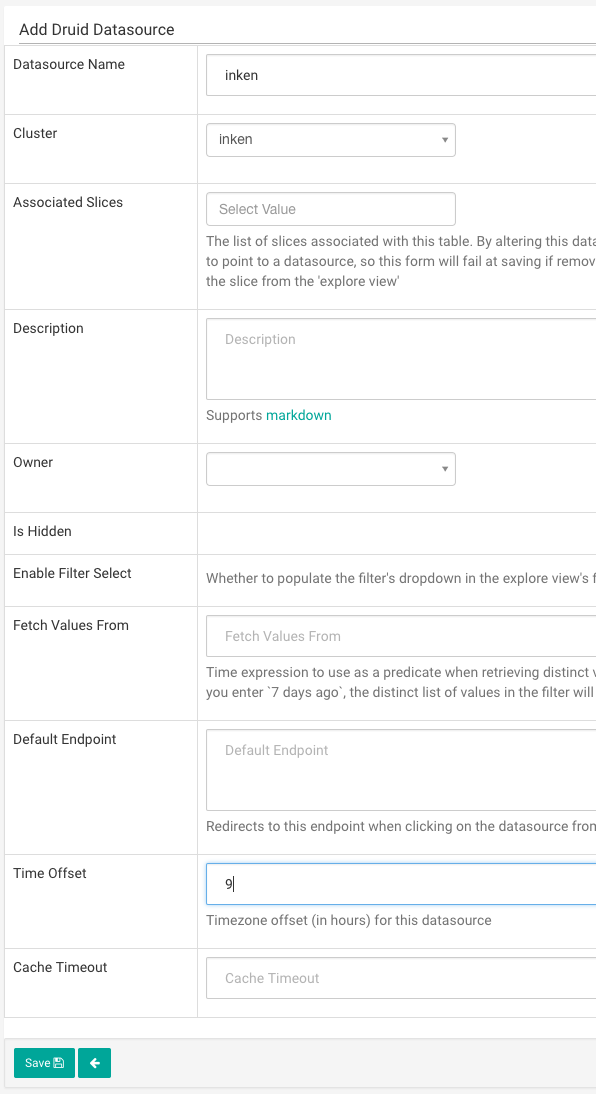
List Druid Column、List Druid Metricも設定ファイルどおりにカラムが追加されているか確認します。
たまにRefresh Druid Metadataやっても読み込まれない場合があるので、その場合は手動でカラムなどを追加します。
Supersetではカラム名に別名をつけることができます。

編集画面の Dimension Spec Jsonで指定します。上記の例はDruid上ではosというカラム名ですが、superset上ではos_nameというカラム名に変更しています。
ただ、現状では名前を変更するとクエリのfilterで指定した際に動かなかったりとサポートされていない機能があるので、そのままの名前を使うほうがいいと思います。
Sliceを作りダッシュボードに貼る
SoucesタブのDruid Datasourcesからデータソースを選び、グラフを作っていきましょう。
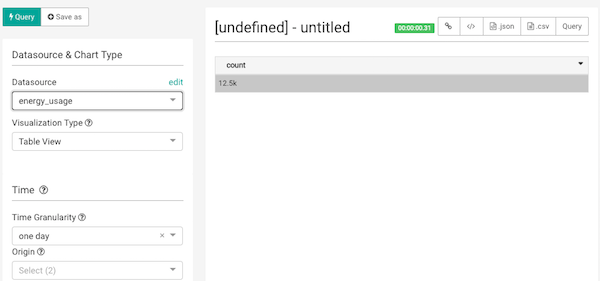
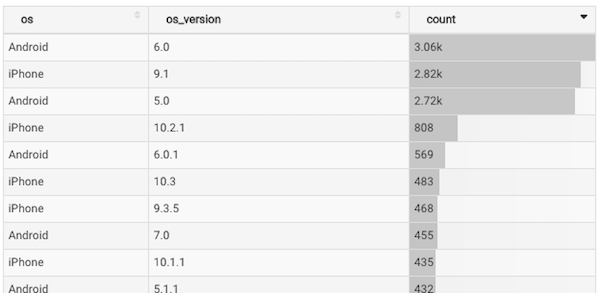
上の例ではTable Viewで各スマホOS使用数を出してみました。
こんな感じで簡単にいろんなグラフやチャートが作れます。
saveしてダッシュボードを新規作成して、完成です。
supersetのダッシュボードは良くできていて、各スライスの大きさや位置がかなり自由に配置できます。
なのでこんなダッシュボードも簡単に作れます。
現状ではダッシュボードのテーマを変えたりはできないみたいですがCSSを記述できるので、自分好みのCSSを当てることもできます。
こんな感じでDruidとさくっとつなげてとても便利なBIツールだと思いました。