以前Druidとpivotを使って、twitterデータを可視化というのをやりましたが、Druidやpivotが一緒にパッケージ化されインストールしやすくなったimplyを使って、もっと簡単にリアルタイム集計をしてみたいと思います。
implyは以下のツールがセットになったイベント集計プラットフォームです。
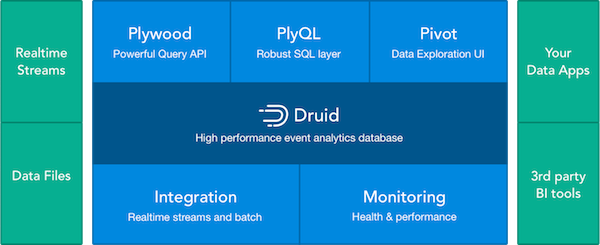
DruidをベースにBIツールのPivotや、DruidのdatasourceをSQLライクに記述できるPlyQL、ラージデータセットを扱う時に便利なJavaScript libraryのPlywoodが含まれています。
implyにはQuickstart用の設定が入ってるので、簡単に試すことができます。
今回はimplyを入れたサーバーとは別のkafkaからデータを取ってきて、pivotで表示するところをこちらのチュートリアルをベースにやっていきたいと思います。
kafkaの準備
まずは、外部のkafkaサーバーを用意し、そこにFluentdとかでJSONで以下のようなデータを入れます。
cd /opt/kafka_2.11/
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic sample --from-beginning
{"date":"2017-04-05 06:23:41","ua_name":"Chrome","ua_category":"smartphone","os":"Android","os_version":"5.0","browser_type":"browser","browser_version":"57.0.2987.110"}
{"date":"2017-04-05 06:31:48","ua_name":"Chrome","ua_category":"smartphone","os":"Android","os_version":"5.0","browser_type":"browser","browser_version":"57.0.2987.110"}
{"date":"2017-04-05 07:42:18","ua_name":"Safari","ua_category":"smartphone","os":"iPhone","os_version":"9.1","browser_type":"browser","browser_version":"9.0"}日時はUTCで入れます。ローカルタイムで入れるとdruidから弾かれます。
implyの設定
kafkaが用意できたらimplyの設定をしていきます。
まずはダウンロードしてきて解凍
tar -xzf imply-2.0.0.tar.gz
cd imply-2.0.0次にdruidのquickstartのkafka設定ファイルを修正します。
vi imply-2.0.0/conf-quickstart/tranquility/kafka.json
一番下にある以下の行をコメントを外します
!p95 tranquility-kafka bin/tranquility kafka -configFile conf-quickstart/tranquility/kafka.json上のコメント外したファイルにdatasourceの設定をします。
中味はこんな感じにしました。
vi conf-quickstart/tranquility/kafka.json
{
"dataSources" : [
{
"spec" : {
"dataSchema" : {
"dataSource" : "sample",
"parser" : {
"type" : "string",
"parseSpec" : {
"timestampSpec" : {
"column" : "date",
"format" : "yyyy-MM-dd HH:mm:ss"
},
"dimensionsSpec" : {
"dimensions" : [
"date",
"ua_name",
"ua_category" ,
"os",
"os_version",
"browser_type",
"browser_version"
]
},
"format" : "json"
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "hour",
"queryGranularity" : "none"
},
"metricsSpec" : [
{
"type" : "count",
"name" : "count"
}
]
},
"ioConfig" : {
"type" : "realtime"
},
"tuningConfig" : {
"type" : "realtime",
"maxRowsInMemory" : "100000",
"intermediatePersistPeriod" : "PT10M",
"windowPeriod" : "PT10M"
}
},
"properties" : {
"task.partitions" : "1",
"task.replicants" : "1",
"topicPattern" : "sample"
}
}
],
"properties" : {
"zookeeper.connect" : "localhost:2181",
"druid.discovery.curator.path" : "/druid/discovery",
"druid.selectors.indexing.serviceName" : "druid/overlord",
"commit.periodMillis" : "15000",
"consumer.numThreads" : "2",
"kafka.zookeeper.connect" : "kafka-server:2181",
"kafka.group.id" : "kafka",
"serialization.format" : "smile",
"druidBeam.taskLocator": "overlord"
}
}
timestampSpecにjsonのdateの形式を入れて、dimensionsにkafkaに入れたjsonの項目名を入れてます。
topicPatternにはkafkaのtopic名、kafka.zookeeper.connectに上で設定したkafkaサーバーのアドレスを入れます。
とりあえずcountだけ計測するようにmetricsSpecを設定します。
implyの起動
以下のコマンドでdruidやpivotなどが一括で起動します。
bin/supervise -c conf/supervise/quickstart.conf起動したらkafkaにデータを流してみましょう。
tail -f var/sv/tranquility-kafka.logこんな感じのログが出ると思います。
2017-04-05 08:38:40,721 [KafkaConsumer-CommitThread] INFO c.m.tranquility.kafka.KafkaConsumer – Flushed {dogakun={receivedCount=2, sentCount=2, droppedCount=0, unparseableCount=0}} pending messages in 0ms and committed offsets in 2ms.
上記みたいにsentCountに値がセットされていたら正常にdruidに取り込まれています。
droppedCountが0じゃない場合、何らかの問題があってdruidに取り込まれていません。
jsonのtimestamp(今回の場合だとdate)がUTCじゃない場合やテストデータなどでdruidのサーバーと時間がかけ離れてる場合にdropされたりします。
PlyQLでデータソースを確認
ちゃんとsentCountされた場合、PlyQLでデータが確認できるようになります。
bin/plyql -h localhost:8082 -q 'show tables'
┌────────────────────────────┐
│ Tables_in_database │
├────────────────────────────┤
│ COLUMNS │
│ SCHEMATA │
│ TABLES │
│ sample │
└────────────────────────────┘
bin/plyql -h localhost:8082 -q 'select * from sample'
┌─────────────────────────────────────────┬──────────────┬─────────────────┬───────┬───────────────┬─────────────┬─────────┬────────────┬─────────┬─────────────┬─────────┬────────┐
│ __time │ browser_type │ browser_version │ count │ date │ ip │ os │ os_version │ referer │ ua_category │ ua_name │ vendor │
├─────────────────────────────────────────┼──────────────┼─────────────────┼───────┼───────────────┼─────────────┼─────────┼────────────┼─────────┼─────────────┼─────────┼────────┤
│ Wed Apr 05 2017 17:52:45 GMT+0900 (JST) │ browser │ 9.0 │ 1 │ 1491382365000 │ 10.48.12.29 │ iPhone │ 9.1 │ NULL │ smartphone │ Safari │ Apple │
│ Wed Apr 05 2017 17:52:47 GMT+0900 (JST) │ browser │ 9.0 │ 1 │ 1491382367000 │ 10.48.12.29 │ iPhone │ 9.1 │ NULL │ smartphone │ Safari │ Apple │
│ Wed Apr 05 2017 17:52:51 GMT+0900 (JST) │ browser │ 57.0.2987.110 │ 1 │ 1491382371000 │ 10.48.12.29 │ Android │ 5.0 │ NULL │ smartphone │ Chrome │ Google │
│ Wed Apr 05 2017 17:52:54 GMT+0900 (JST) │ browser │ 57.0.2987.110 │ 1 │ 1491382374000 │ 10.48.12.29 │ Android │ 5.0 │ NULL │ smartphone │ Chrome │ Google │
│ Wed Apr 05 2017 17:52:57 GMT+0900 (JST) │ browser │ 9.0 │ 1 │ 1491382377000 │ 10.48.12.29 │ iPad │ 9.1 │ NULL │ smartphone │ Safari │ Apple │
└─────────────────────────────────────────┴──────────────┴─────────────────┴───────┴───────────────┴─────────────┴─────────┴────────────┴─────────┴─────────────┴─────────┴────────┘こんな感じでSQLライクにデータを参照することができます。
Pivotの設定
imply入れたサーバーの9095ポートにアクセスします。
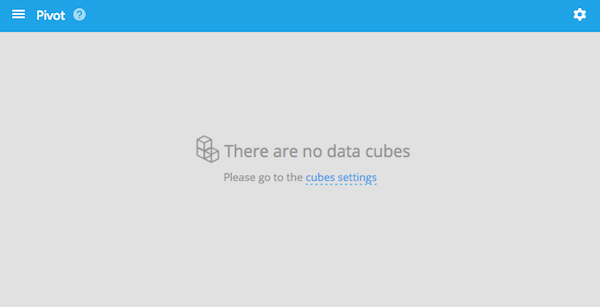
真ん中のcubes settingsまたは右上の設定アイコンからData Cubesを選んで、新しいdata cubeを作ります。
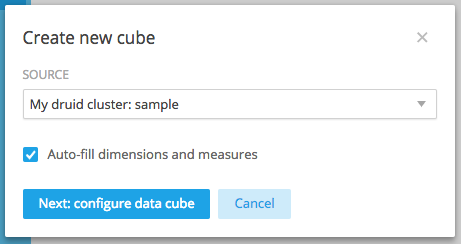
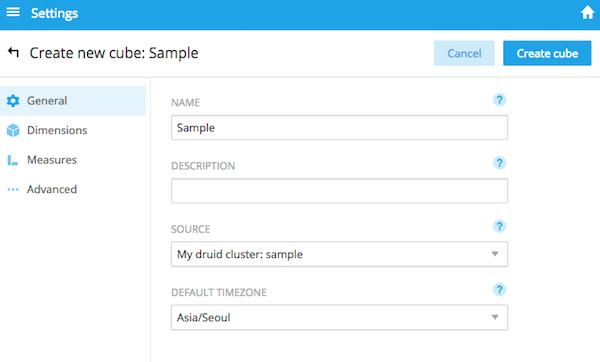
sourceにデータソース名を選択し、Timezoneは日本がないので Asia/Seoulを選択します。
Create cubeすると、data cubeが作られます。
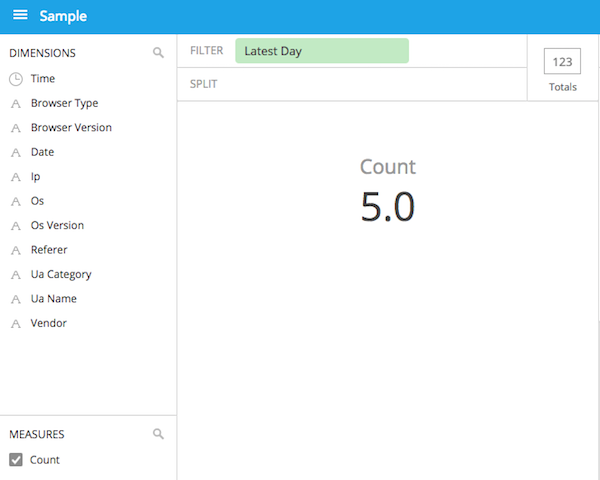
今作ったdata cubeを選択するとこんな感じでCountが表示されます。
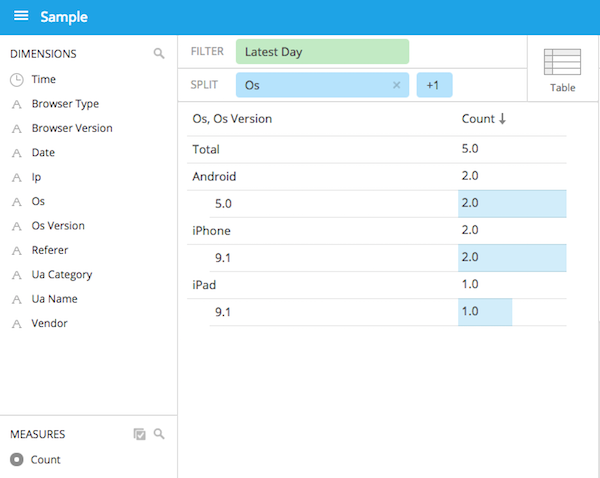
あとはディメンションを設定したりしてこんなグラフが作れます。
こんな感じで、implyとしてまとまったパッケージになったおかげで、別々に入れていたときよりも簡単に試せるようになりました。