前回、Cloudera Managerを使ってHDFSクラスタを構築しました。
今回はこのHDFS上でApache Sparkを動かします。
Apache Sparkを扱うOSSのGUIをいろいろ探してみたのですが、現状ではIPython + notebook最強伝説です。
というわけでまずはMesosのマスター/スレーブを構築していきたいのですが、その前に、Mesosとは何か?です。
0. Mesosとは
■ Mesos
分散アプリケーションもしくはフレームワークに対して効率的なリソース分離、共有を提供するクラスタ管理アプリケーションです。
つまり、分散アプリケーションで実行されるタスクを管理し、効率的にリソース分配を行うものです。
要はYARNと同じ役割ですが、YARNとの違いは下記に詳しい記述がありました。
[Mesos]Hadoop YARNとApache Mesosの違いって何?
1. Mesosのインストール
※この作業はMesosマスター/スレーブの全台で行います。
yumでインストールします。
MesosはZooKeeperに依存しているため、ZooKeeperのインストールも必要になるのですが、ここでは前回Cloudera ManagerでインストールしたZooKeeperクラスタを使用します。
# mesosphereリポジトリをインストール rpm -Uvh http://repos.mesosphere.io/el/6/noarch/RPMS/mesosphere-el-repo-6-2.noarch.rpm # mesosとmarathonをインストール yum -y install mesos marathon
2. Mesosの設定ファイルを修正
Mesosの設定ファイルを環境に合わせて変更するのですが、当然マスターとスレーブで設定ファイルの内容が異なってきます。
今回私は4台のサーバに対し、マスター1台+スレーブ3台のようにロールを割り当てますが、
マスター4台+スレーブ4台のように全ホストでマスターとスレーブを実行することも可能です。
2.1. マスターの設定
マスターでは、ログディレクトリやworkディレクトリの他に、quorumやZooKeeperの設定を行います。
# マスター用のテンプレートを利用します。 cp /usr/etc/mesos/mesos-master-env.sh.template /usr/etc/mesos/mesos-master-env.sh vi /usr/etc/mesos/mesos-master-env.sh ~ export MESOS_log_dir=/var/log/mesos export MESOS_work_dir=/var/lib/mesos # マスター1台なので1。 export MESOS_quorum=1 export MESOS_zk="zk://xxx.xxx.xxx.106:2181,xxx.xxx.xxx.107:2181,xxx.xxx.xxx.108:2181/mesos" ~
マスターとスレーブを定義します。
※FQDNでも構いません。
# マスターの定義 vi /usr/etc/mesos/masters ~ xxx.xxx.xxx.109 ~ # スレーブの定義 vi /usr/etc/mesos/slaves ~ xxx.xxx.xxx.106 xxx.xxx.xxx.107 xxx.xxx.xxx.108 ~
最後にデプロイ用環境設定も利用できるようにします。
mv /usr/etc/mesos/mesos-deploy-env.sh.template /usr/etc/mesos/mesos-deploy-env.sh
以上でマスターの設定は完了です。
2.2. スレーブの設定
スレーブでは、ログディレクトリ、workディレクトリとマスターの設定を行います。
# スレーブ用のテンプレートを利用します。 cp /usr/etc/mesos/mesos-slave-env.sh.template /usr/etc/mesos/mesos-slave-env.sh vi /usr/etc/mesos/mesos-slave-env.sh ~ # Mesosマスターのアドレス export MESOS_master=xxx.xxx.xxx.109:5050 export MESOS_log_dir=/var/log/mesos-slave export MESOS_work_dir=/var/run/mesos ~
スレーブの設定は以上ですが、MesosマスターホストのMesos起動ユーザから公開鍵認証でsshログインできない場合は、sshログインできるようにしておきます。
3. Mesosの起動
Mesosを起動します。
まずはマスターから。
# マスターで実行します。 /usr/sbin/mesos-start-masters.sh
正常に起動すれば、MESOS_log_dirに設定したディレクトリにログが出力されるはずです。
次にスレーブを起動します。
# マスターで実行します。※このためにsshログインを可能な状態にしておきました。 /usr/sbin/mesos-start-slaves.sh
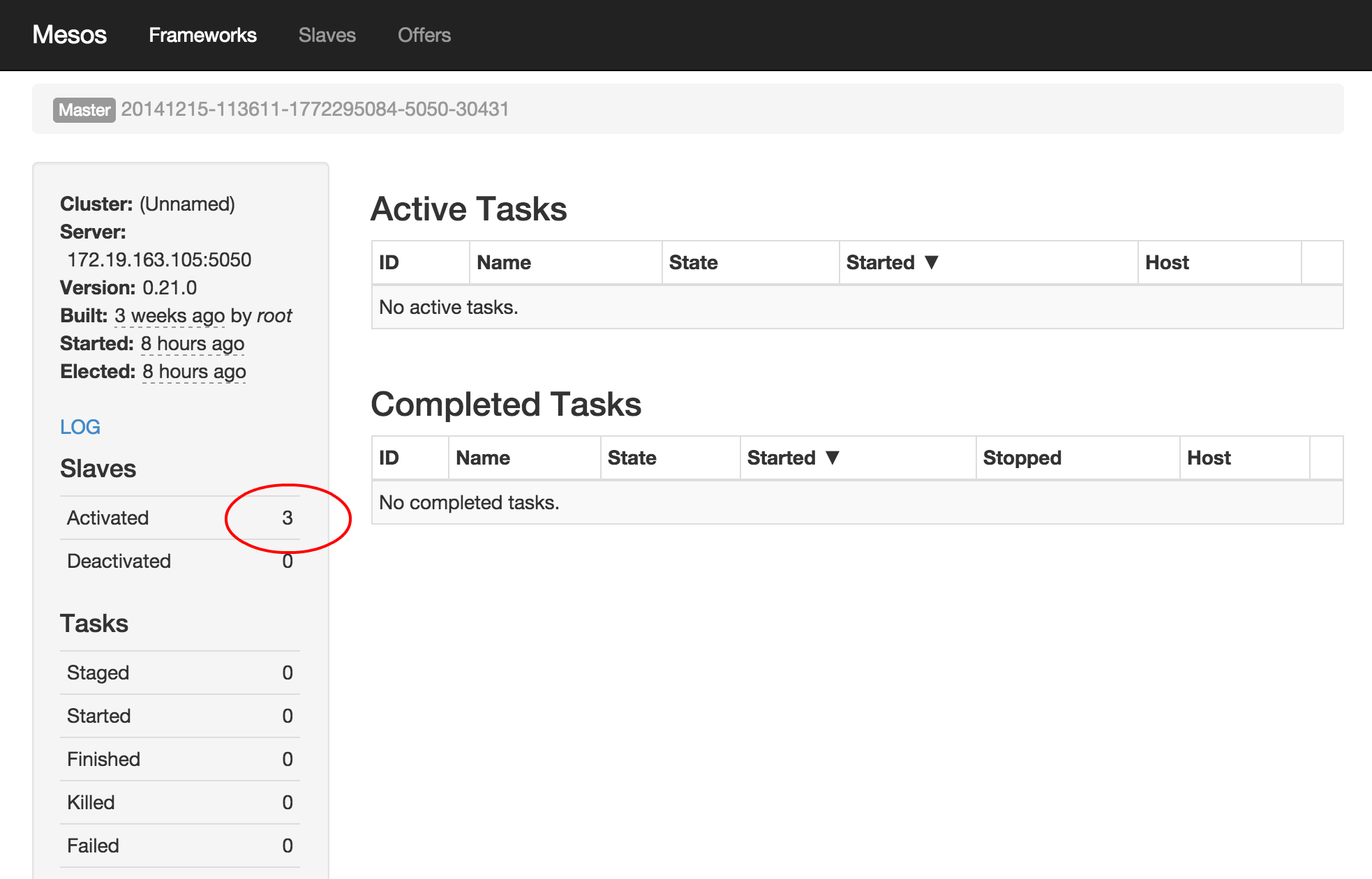
スレーブが正常に起動しているかどうかはブラウザから確認できます。
マスターのGUI
http://mesosmaster:5050
を開きます。
スレーブが正常に起動していればサイドバーのSlaves-Activatedに起動したスレーブの数が表示されているはずです。
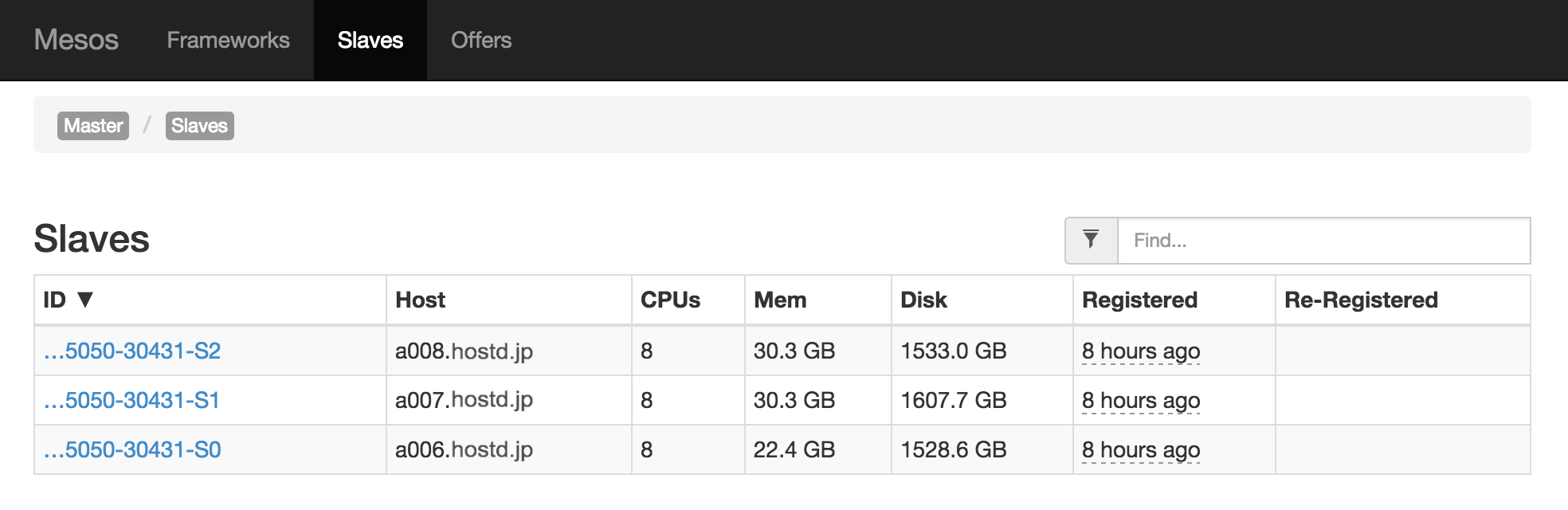
またメニューからSlavesを開くとマスターに接続しているスレーブの情報を見ることができます。
4. Sparkのビルド
Mesosが起動したらいよいよSparkのビルドです。
mesosphere.comにあるチュートリアルを参考にしました。
http://mesosphere.com/docs/tutorials/run-spark-on-mesos/
いずれか1台のホストで作業を行います。
JDKのインストール
Sparkのビルドにはjdkの1.6が必要になります。
入っていない場合はyumでopenjdkをインストールしておきます。
yum install -y java-1.6.0-openjdk java-1.6.0-openjdk-devel
Mavenのインストール
SparkのビルドはMavenを使うのでMavenもインストールします。
cd /opt wget http://www.trieuvan.com/apache/maven/maven-3/3.2.3/binaries/apache-maven-3.2.3-bin.tar.gz tar zxvf apache-maven-3.2.3-bin.tar.gz ln -nfs apache-maven-3.2.3 maven ln -nfs /opt/maven/bin/mvn /usr/bin/mvn mvn -v
Sparkのソースコードを入手
GitHubにあるApache Sparkのリポジトリからソースコードを取得します。
git clone https://github.com/apache/spark
さて、いよいよSparkをビルドします。
私はSparkSQLを使用するため、SPARK_HIVE変数にtrueを設定しています。
# Hadoop情報を設定 export HADOOP_HOME=/usr/lib/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR="$HADOOP_HOME/lib/native" export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib" # HadoopのバージョンとSPARK_HIVE変数を指定してsbtを実行。 SPARK_HADOOP_VERSION=2.5.0-cdh5.2.0 SPARK_HIVE=true sbt/sbt clean assembly
次に設定ファイルの変更を行います。
・conf/spark-env.sh
Mesosの情報やSparkマスターの情報、Hadoopホームなどを設定します。
mv conf/spark-env.sh.template conf/spark-env.sh vi conf/spark-env.sh ~ export MESOS_NATIVE_LIBRARY=/usr/local/lib/libmesos.so export MASTER=mesos://zk://xxx.xxx.xxx.106:2181,xxx.xxx.xxx.107:2181,xxx.xxx.xxx.108:2181/mesos export SPARK_HOME=/opt/spark export DEFAULT_HADOOP_HOME=/usr/lib/hadoop ~
・conf/spark-defaults.conf
ドライバー/ワーカーのメモリ設定を行います。
mv conf/spark-defaults.conf.template conf/spark-defaults.conf vi conf/spark-defaults.conf ~ spark.executor.memory 12g spark.driver.memory 8g spark.python.worker.memory 2g ~
・bin/spark-class
jvmのヒープサイズが小さすぎるので増やします。
※jdk1.8で動かす場合は-XX:MaxPermSizeオプション自体がなくなっているので下記は不要です。
vi bin/spark-class ~ #JAVA_OPTS="-XX:MaxPermSize=128m $OUR_JAVA_OPTS" JAVA_OPTS="-XX:MaxPermSize=2048m $OUR_JAVA_OPTS" ~
最後にdistributionファイルを作成します。
time ./make-distribution.sh --tgz -Phive -Phive-thriftserver -Phadoop-2.5 -Dhadoop.version=2.5.0-cdh5.2.0 -DskipTests
するとディレクトリが圧縮されたtgzファイルが出来上がります。
できたファイルはSparkのホームディレクトリとしたい箇所におきます。
※私はSparkのホームディレクトリを/opt/sparkとしたいので/optに置きました。
cp spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgz /opt/ cd /opt tar zxvf spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgz ln -nfs /opt/spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0 /opt/spark
5. Sparkビルドファイルの配布
ビルドしてできたファイル(spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgz)を他のサーバに配布します。
scp spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgz a006.hostd.jp:~ scp spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgz a007.hostd.jp:~ scp spark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgz a008.hostd.jp:~
配布したホストでも/optにspark-1.3.0-SNAPSHOT-bin-2.5.0-cdh5.2.0.tgzを置いて解凍し/opt/sparkをSparkのホームディレクトリとします。
6. Mesosに設定を追加
最後の作業です。Mesosマスターで作業します。
mesos-deploy-env.shにSPARK_HOMEの記述を追加します。
vi /usr/etc/mesos/mesos-deploy-env.sh ~ export SPARK_HOME=/opt/spark ~
Mesosマスター/スレーブともに再起動します。
/usr/sbin/mesos-stop-cluster.sh /usr/sbin/mesos-start-masters.sh /usr/sbin/mesos-start-slaves.sh
7. spark-shellを起動してみる
さてここまで終えたらspark-shellを起動してみます。
cd /opt/spark bin/spark-shell
正常に起動したら下記のように表示されます。
14/12/17 10:22:07 INFO SparkUI: Started SparkUI at http://a009.hostd.jp:4040
2014-12-17 10:22:07,349:31063(0x7f8e47fff700):ZOO_INFO@log_env@712: Client environment:zookeeper.version=zookeeper C client 3.4.5
:
I1217 10:22:07.354766 31134 group.cpp:385] Trying to create path '/mesos' in ZooKeeper
I1217 10:22:07.357442 31132 detector.cpp:138] Detected a new leader: (id='6')
I1217 10:22:07.358057 31129 group.cpp:659] Trying to get '/mesos/info_0000000006' in ZooKeeper
I1217 10:22:07.359076 31133 detector.cpp:433] A new leading master (UPID=master@xxx.xxx.xxx.105:5050) is detected
I1217 10:22:07.359323 31128 sched.cpp:234] New master detected at master@xxx.xxx.xxx.105:5050
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.3.0-SNAPSHOT
/_/
Using Python version 2.7.8 (default, Aug 21 2014 18:22:21)
SparkContext available as sc.
「ZOO_INFO@」や「’/mesos’ in ZooKeeper」のあたりから、ZooKeeperとMesosに接続していることがわかります。
またhttp://a009.hostd.jp:4040がSparkUIのURLだと表示されているのでブラウザで開いてみます。
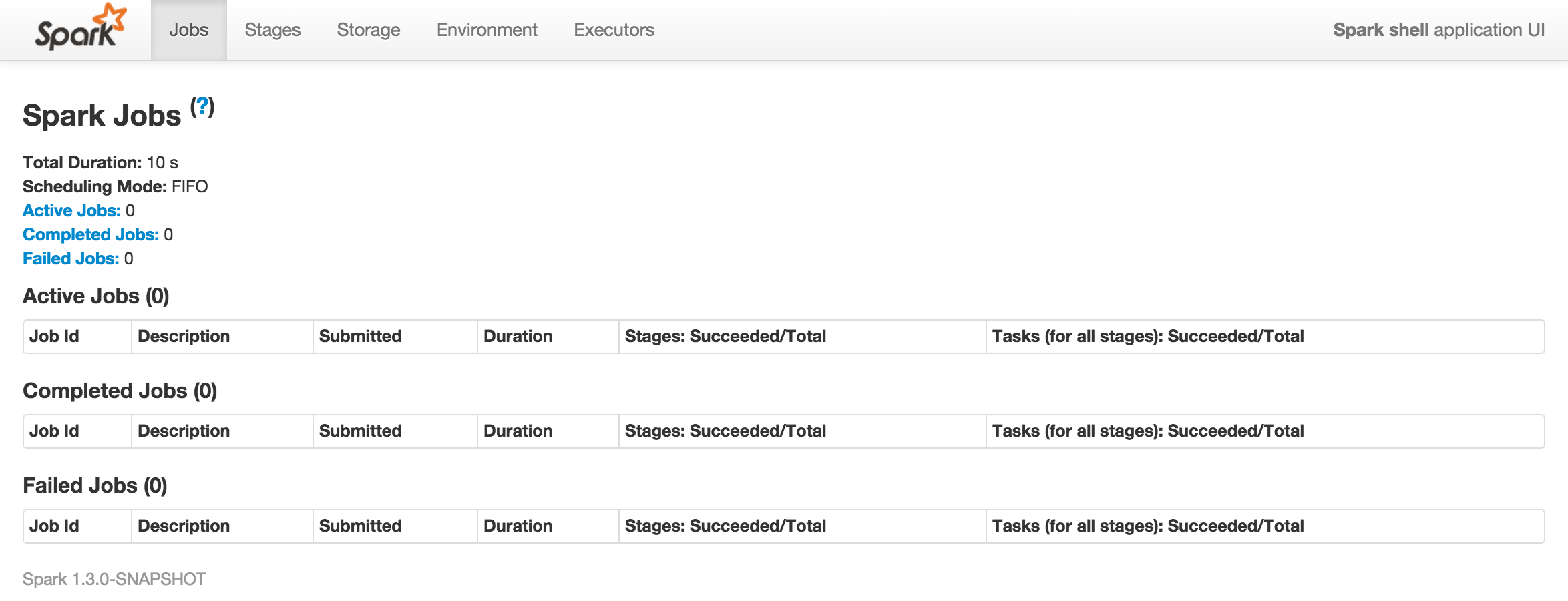
現段階では何も表示されません。
mesosphereのチュートリアルにあるテストスクリプトを実行してみます。
scala> val data = 1 to 10000 data: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, ... scala> scala> val distData = sc.parallelize(data) distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at :14
1万件のデータを作成してRDDを作成しました。
次に、これに対してフィルタリングを行います。
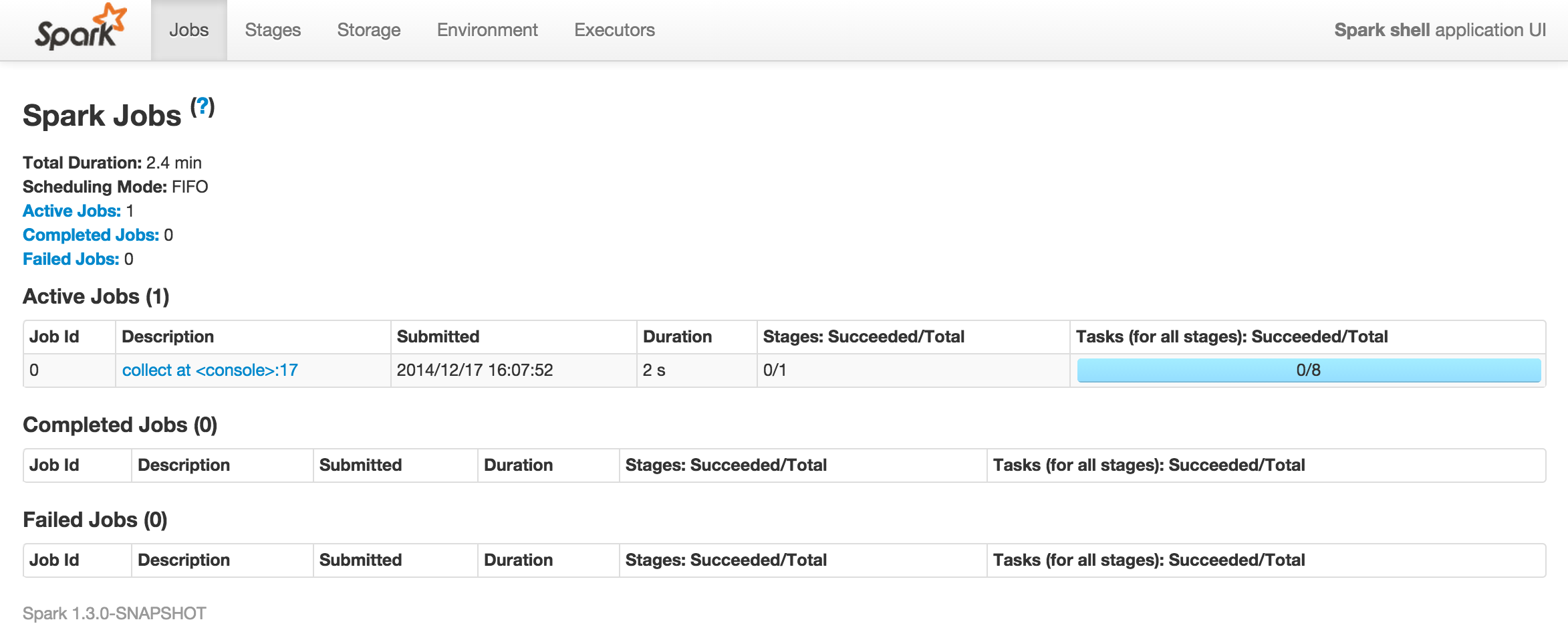
distData.filter(_< 10).collect() 14/12/17 16:07:52 INFO SparkContext: Starting job: collect at <console>:17 14/12/17 16:07:52 INFO DAGScheduler: Got job 0 (collect at <console>:17) with 8 output partitions (allowLocal=false) : 14/12/17 16:07:55 INFO DAGScheduler: Job 0 finished: collect at <console>:17, took 2.674692 s res0: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
ここで先ほどのSparkUIを再び開いてみます。
すると、下記のようにタスクが実行されている様子が表示されます。
Mesosの方も見てみます。
こちらもスレーブたちがタスクを実行していることがわかります。
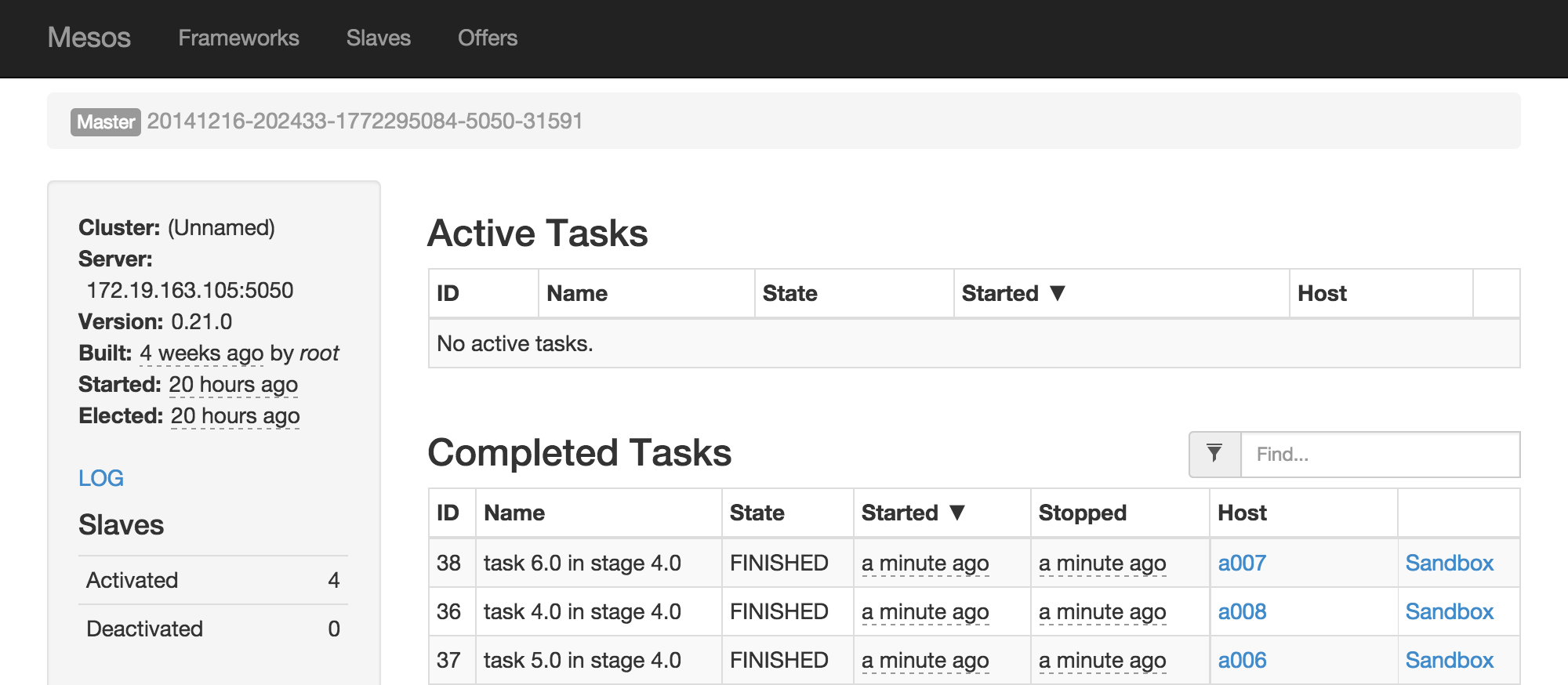
ここまで確認できたらspark-shellをexitし、一旦終了します。
8. IPython notebookからSparkを使う
さていよいよIPython notebookの出番です。
今度はspark-shellではなくpysparkを使うのですが、pythonが入っていない場合はanacondaでさくっといれてしまいましょう。
※この後matplotを使うためanacondaがオススメです。
continuum.io | Download Anaconda
IPython notebookのデフォルトパラメータを設定
IPython notebookのコンフィギュレーションを行います。
ipythonのホームディレクトリ、notebookがバインドするアドレス、ログ出力を設定します。
ipython profile create vi ~/.ipython/profile_default/ipython_config.py # c.TerminalIPythonApp.ipython_dir = u'' c.TerminalIPythonApp.ipython_dir = u"$HOME/.ipython" # c.TerminalInteractiveShell.logstart = False c.TerminalInteractiveShell.logstart = True # The name of the logfile to use. # c.TerminalInteractiveShell.logfile = '' c.TerminalInteractiveShell.logfile = '/var/log/ipython' vi ~/.ipython/profile_default/ipython_notebook_config.py # c.NotebookApp.ip = 'localhost' c.NotebookApp.ip = 'a009.hostd.jp' # c.NotebookApp.port = 8888 c.NotebookApp.port = 8888
IPYTHON_OPTSを指定してpysparkを起動します。
IPYTHON_OPTS="notebook --matplotlib inline" nohup bin/pyspark &
ブラウザからIPython notebookを開きます。

「New Notebook」をタップして新しいnotebookを作成します。
ここにSparkのサンプルにも上がっているwordcountを実装します。
notebookはwordcountにリネームしておきます。
下記はREADME.md内の単語を出現回数順に並べて折れ線グラフで表示したものです。
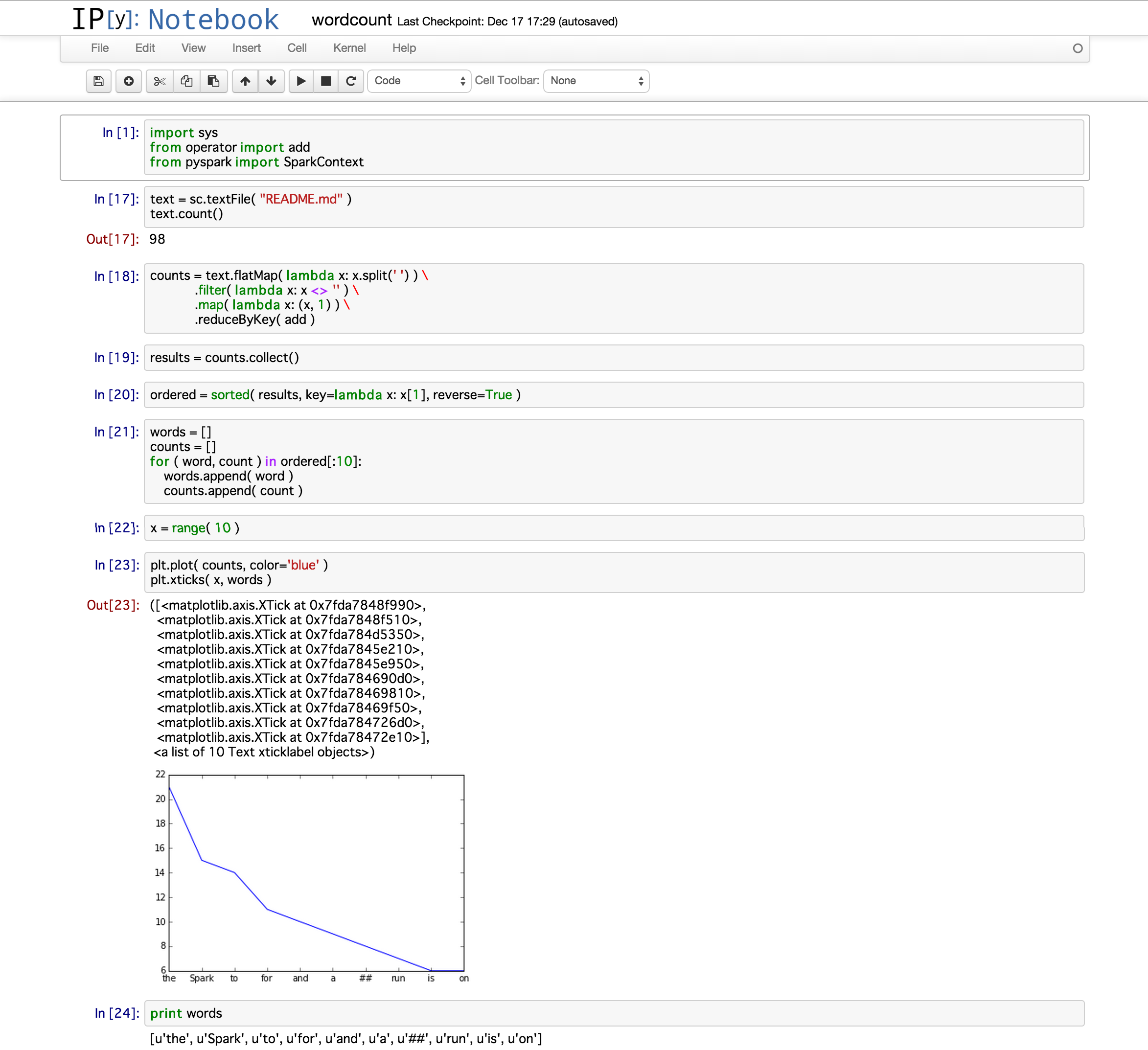
↑の内容。
import sys
from operator import add
from pyspark import SparkContext
# README.mdをRDDに読み込む
text = sc.textFile( "README.md" )
# 行数をカウント -- 別になくて良い
text.count()
# 単語をスペースで区切り、ブランクを除外、単語ごとにカウント
counts = text.flatMap( lambda x: x.split(' ') ) \
.filter( lambda x: x <> '' ) \
.map( lambda x: (x, 1) ) \
.reduceByKey( add )
# 集計
results = counts.collect()
# 出現回数の多い順に並び替え
ordered = sorted( results, key=lambda x: x[1], reverse=True )
words = []
counts = []
# 上位10件のみグラフに表示する
for ( word, count ) in ordered[:10]:
words.append( word )
counts.append( count )
x = range( 10 )
# グラフの描画
plt.plot( counts, color='blue' )
plt.xticks( x, words )
print words
データの分析からグラフの描画までがあっという間にできてしまいます。
分析ツールとして非常に強力なものであることがお分かり頂けましたでしょうか。