2018年3月16日(金)に行われたScalaMatsuri2018トレーニングDAYでビッグデータについてお話させて頂きました。
ビッグデータで弱小卓球部を強くしよう!というふざけた内容です。
行ったデモの内容
ストリーミング・データ
Apache Zeppelinでデータの取得〜可視化まで行います
依存のロード
%spark.dep
z.reset()
z.load("org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0")
z.load("mysql:mysql-connector-java:6.0.6")
バージョン確認
%spark scala.util.Properties.versionString spark.version
JSONをパースする構造体をcase classで作成
%spark
import org.apache.spark.sql.{Encoder, Encoders}
case class Track (
id: Long,
player: String,
speed: Double,
x: Double,
y: Double,
z: Double,
time: java.sql.Timestamp
)
作成したcase classからEncoderを作成する
%spark // スキーマを取得することができたり、json.read時に文字列をパースすることができます。 val encoder = Encoders.product[Track] print(encoder)
kafkaからリアルタイムデータを取得して、JSONをDataSetに展開します
%spark
val ds = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "10.146.0.3:9092,10.146.0.5:9092,10.146.0.6:9092")
.option("startingOffsets", "latest")
.option("subscribe", "takkyu")
.load()
.select($"value" cast "string" as "json")
.select(from_json($"json", encoder.schema) as "takkyu")
.select("takkyu.*")
Kafkaから取得したデータをメモリに書き出し続けます
%spark
val query = ds
.writeStream
.queryName("takkyu_table")
.format("memory")
.start()
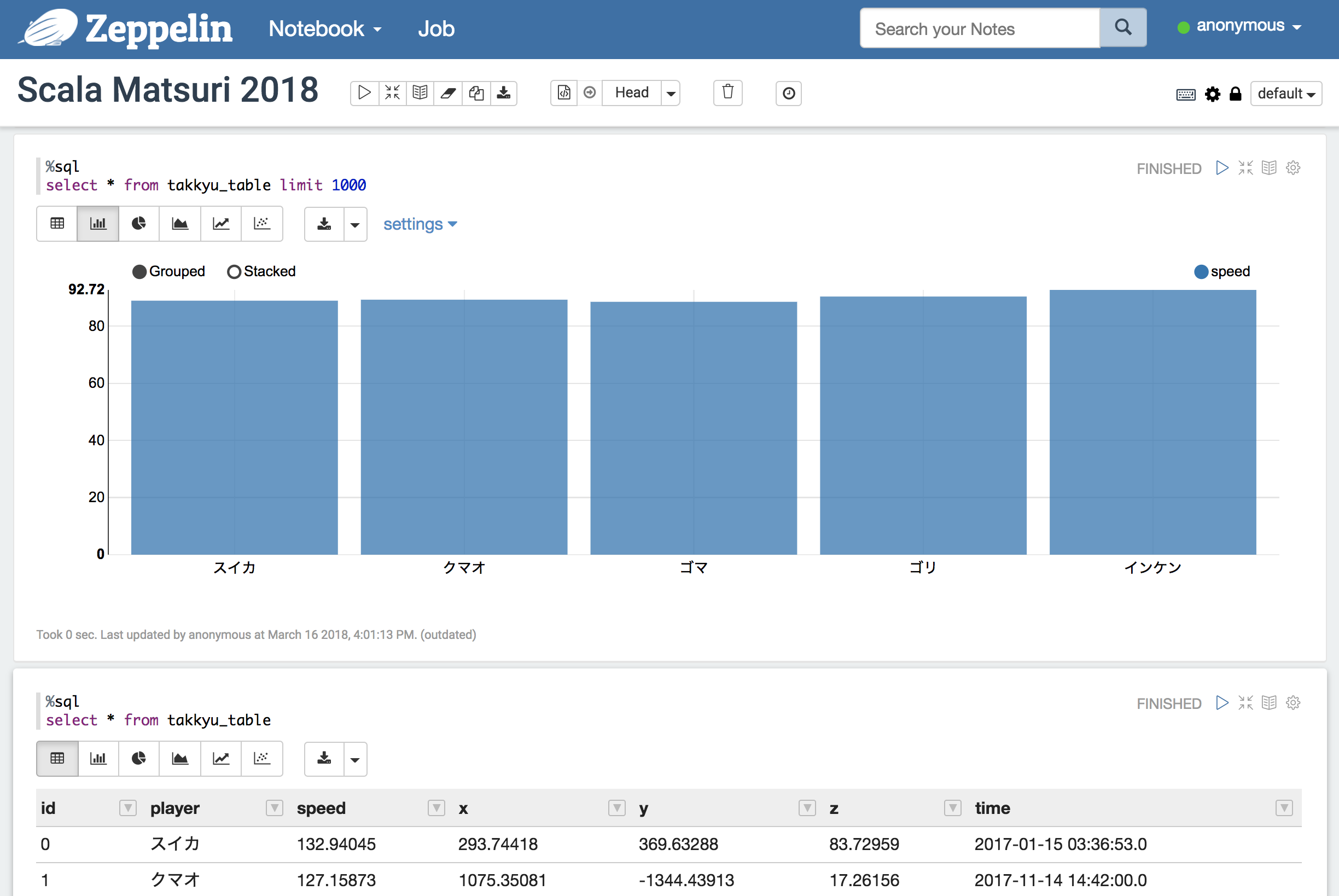
メモリに展開したデータを抽出します
%sql select * from takkyu_table limit 1000
MySQLから部員情報(マスタ)を取得します
%spark
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://10.146.0.11:3306/takkyu?useUnicode=true&characterEncoding=utf8")
.option("dbtable", "buin")
.option("user", "******")
.option("password", "******")
.load()
.select("*")
.createOrReplaceTempView("buin")
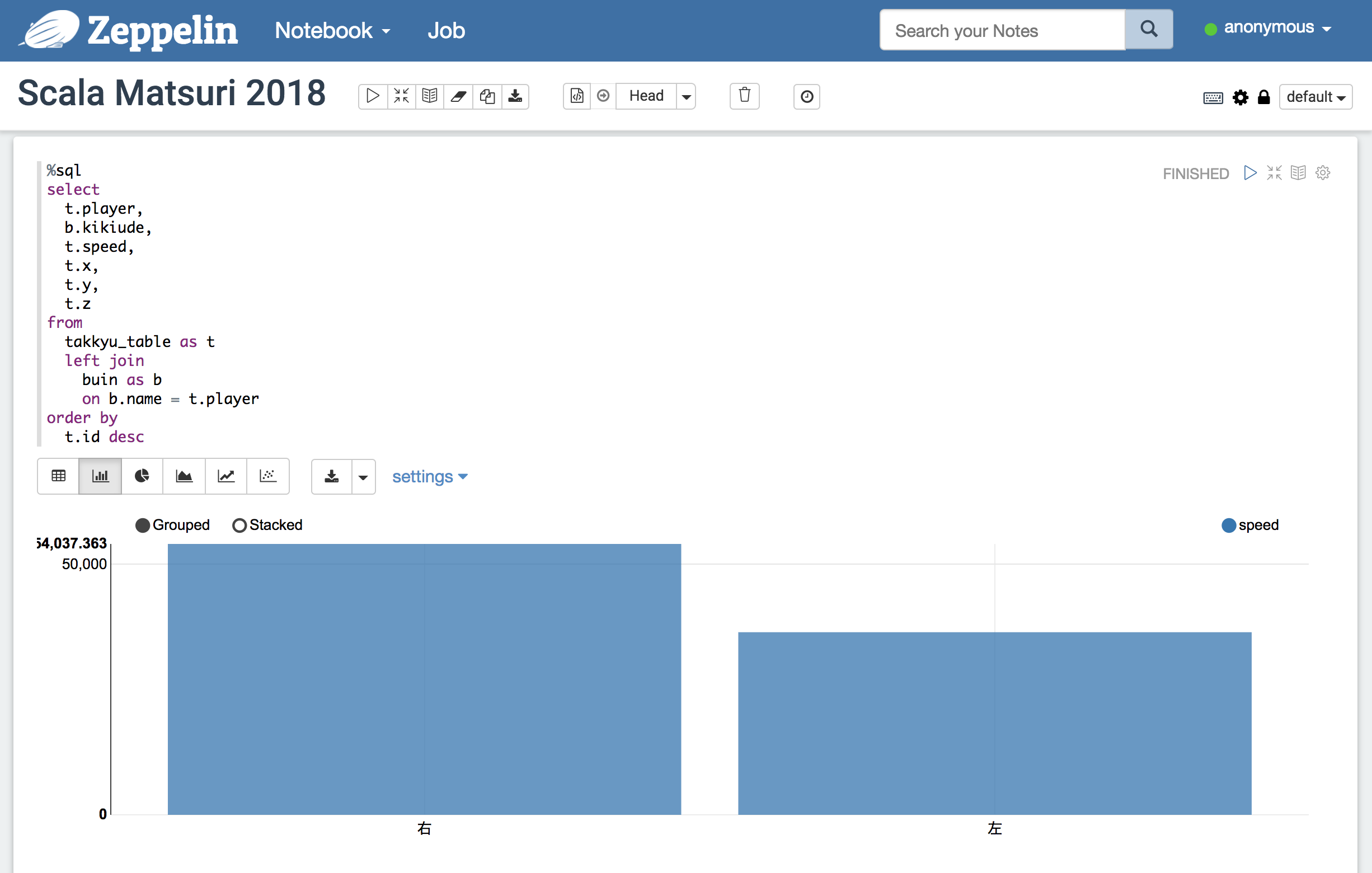
MySQLから取得したマスタとKafkaから取得したストリーム・データをJOINします
%sql
select
t.player,
b.kikiude,
t.speed,
t.x,
t.y,
t.z
from
takkyu_table as t
left join
buin as b
on b.name = t.player
order by
t.id desc
例えば、利き腕別のスピード平均をグラフ化したりできます。