この記事はGeek Women Advent Calendar 2015 18日目のために書きました。
2015年12月1日-3日の日程でStrata+Hadoop World Singaporeが開催されました。
Strata+Hadoop Worldは世界最大規模のビッグデータ・カンファレンスなのですが、アジアでの開催は今年が初めてです。
アジアにおけるビッグデータの活用とアジア市場でのビッグデータの温度感を見たくて、こちらのカンファレンスに参加してきました。
http://conferences.oreilly.com/strata/big-data-conference-sg-2015

中でも特に面白かったセッションをいくつかご紹介させて頂きたいと思います。
面白かったセッション
Hadoop’s storage gap: Resolving transactional access/analytic performance trade-offs with Kudu

clouderaの中に人によるclouderaが開発しているApache Kudoのアーキテクチャのセッションです。
Apache Kudo はOpen Sourceで、HDFSとHBaseのいいとこ取りをしたようなミドルウェアです。
Kudoは1,000億行のレコードを高速に扱え、シーケンシャルな読み込み・ランダムな読み込みとシーケンシャルな書き込み・ランダムな書き込みを同時に行えるそうです。
Application of Spark on analyzing massive GIS data for a large number of mobile objects
NTTデータ・土橋さんとIHI鈴木さんによるモバイルのための地理情報解析のセッションでした。
日本におけるApache Sparkを用いた分析のユース・ケースは大変関心が高く、会場から人が溢れそうなほどでした。
NTTデータ土橋さんとIHI鈴木さんによるSpark分析のセッションが大盛況過ぎて立ち見が溢れてる・・・ https://t.co/LzyypPJZY7 #StrataHadoop pic.twitter.com/LImnS1gDSw
— Yuli Inoue (@iyunoriue) 2015, 12月 2
Apache Spark1.5で導入されたTungstenを利用してのCPUボトルネックケースにおける性能改善のお話などは技術的もに大変興味深いものでした。
Using machine learning to identify fraud on Telecom networks
今回のStrata+Hadoop world Singaporeではフラウド検知のセッション及びチュートリアルがいくつかありました。 このセッションもその1つです。 世界的にフラウド検知の重要性が増しているということなのでしょうか。 初日のチュートリアルでもフラウド検知があったのですが、こちらの方が面白かったです。 Machine Learningライブラリを元素記号表で表したり、  Flight MachineとMachine Learningをかけて、飛行船になぞらえてMachine Learningの歴史を解説したり。
Flight MachineとMachine Learningをかけて、飛行船になぞらえてMachine Learningの歴史を解説したり。
History of (Flight) Machine Learning #StrataHadoop pic.twitter.com/rqsNMrok5d
— Toru Shimogaki (@shimtoru) 2015, 12月 2
この画像を見ているだけでも楽しくなってしまいます( ´∀`)
GDELT + BigQuery: Understanding global society through SQL
Googleの方によるGDELTのデータを活用してBigQueryで分析するお話でした。
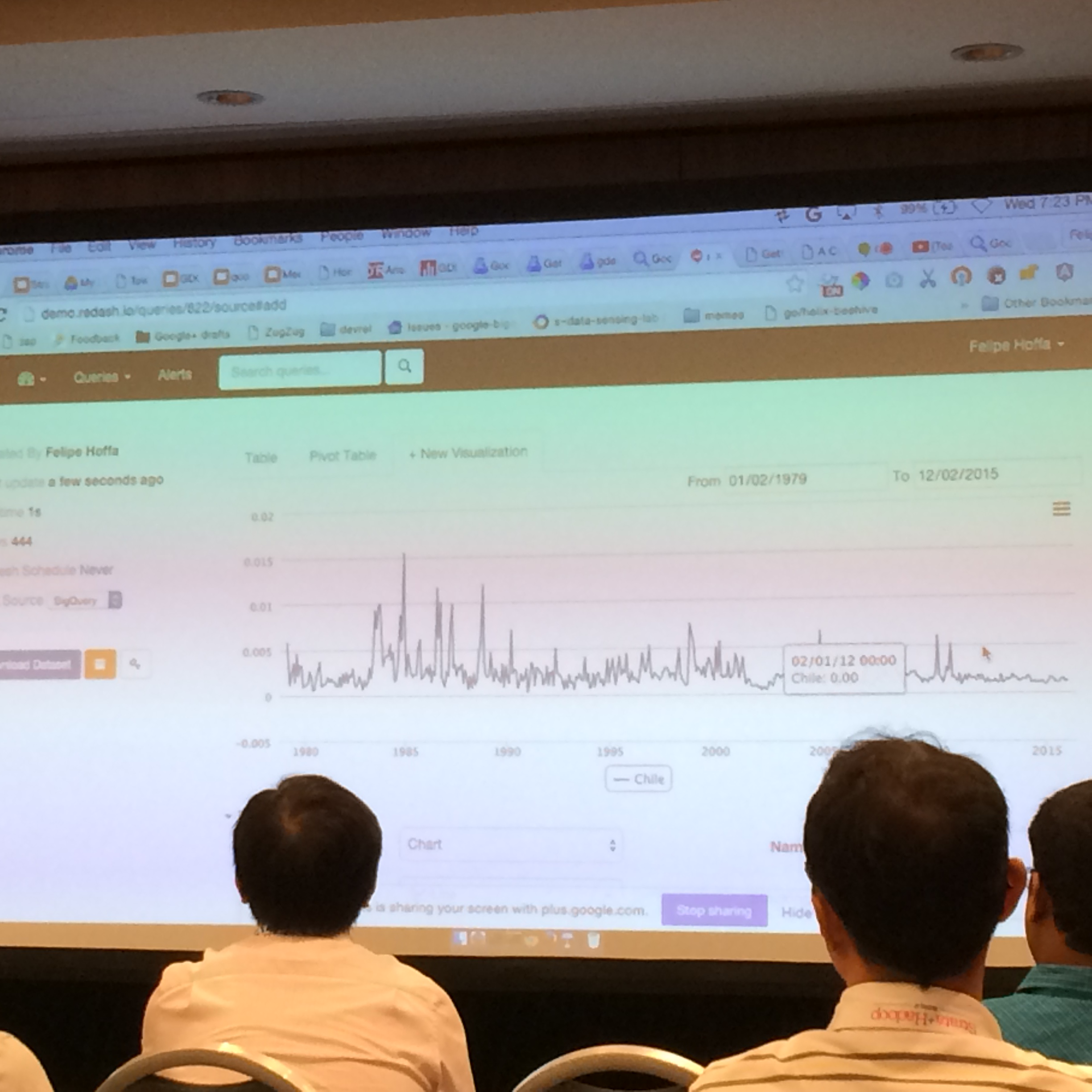
Googleの中の人もre:dash使っているんだなと。。。
BigQueryのGUIはre:dashがスタンダード化しつつありますね。
また個人的にはGDELTのデータが使えることがわかっただけでも、このセッションに出た価値がありました!
Druid: Power Applications to Analyze Sensor Data
このセッションはdruidの開発者によるdruidの紹介だったのですが、個人的にdruidは今一番注目しているミドルウェアなので、とても面白かったです。
druidはサブ・セカンド・クエリを実行できるストリーム処理基盤です。
GoogleのDremelやPowerDrillnにインスパイアされているというだけあって、リアルタイム性と高速性が売りです。
※あと、他にはあまりないサブ・セカンド・クエリ。
以前見た時には、良いGUIがない(と思ってた)ので若干微妙だと思ったのですが、今回デモはそんな懸念を払拭するものでした。
druidではpivotをWebGUIとして使えるようになっており、pivotからdruidを操作するデモを見せてくれました。
綺麗な写真が撮れなかったのでpivotのGithubリポジトリから借りてきました。

Tableauライクな直感的なUIです。2016年流行るんじゃないかと期待しています。
総括
今回のStrata+Hadoop World Singaporeでは、参加したセッションの8割でApache Kafkaの話が出たように思います。
世界的に見てもApache Kafkaは今ストリーム基盤のスタンダードなんだと感じました。
@iyunoriue うちのお客さんでも使ってる人いますね.やはりconsumerが複数いても大丈夫なのが間に挟む大きな理由っぽいですが
— Mr. Fiber (@repeatedly) 2015, 12月 2
cofluentの方と話しましたが、Kafkaを使ってストリーム基盤を実現するためのコンサルタントっぽい仕事がそれなりにあるらしいです。需要は西海岸が多いんですが。日本でもメジャーですよ、と伝えてみました https://t.co/fUrGIECDNc
— Masaru Dobashi (@masaru_dobashi) 2015, 12月 2
それと昨年Strata+Hadoop World Europeに参加した時は機械学習・ストリーミング・Apache Sparkの事例は少なく、紹介にとどまっていたと思ったのですが、今年は事例もすごく増えました。
実際使われて、知見が溜まっているということなんでしょうかね。
また日本のカンファレンスだとあまり女性を見かけないのですが、このカンファレンスではアジア各国の女性を見ました。

日本はアジアレベルで見ても女子エンジニア少ないのかな、と思いました。
おまけ
カンファレンスの食事風景w
アジア開催なので食事もアジア料理でした。アジアン美味しい❤


カンファレンス中は朝ごはん、モーニング・ブレイク、ランチ、ティー・タイム、バケットと5食出てくるので太ります:(;゙゚’ω゚’):
シンガポール
12月なのでシンガポールは街中がクリスマスでした。

チキンライス美味しすぎです♪

シンガポールはごはん美味しいしインドやイスラム街があって楽しいところでした。
来年もStrata+Hadoop World参加したいです。