Strata+Hadoop Worldカンファレンスの2日目と3日目です。
2日目、3日目は注目セッションもたくさんあったのですが、スポンサー・パビリオンも外せませんでした。
2〜3日目の注目セッション
SAMOA: A Platform for Mining Big Data Streams
Gianmarco De Francisci Morales (Yahoo Labs)
Yahoo Labsが開発したストリーミング機械学習フレームワーク、SAMOAの話です。
サイトにスライドもあがっています。
A Gentle Introduction to Apache Spark and Clustering for Anomaly Detection
Sean Owen (Cloudera)
KDD Cup ‘99のデータを使ってSparkでK-meansクラスタリングを行う話。
Building a Unified Data Pipeline in Spark
Aaron Davidson (Databricks)
Scala Matsuri2014の際にも来日してくださったDatabricksのAaronさんのセッション。
内容はScala Matsuriと同様、Spark Streamingを使ってTwitterツイートの言語推定するというものでした。
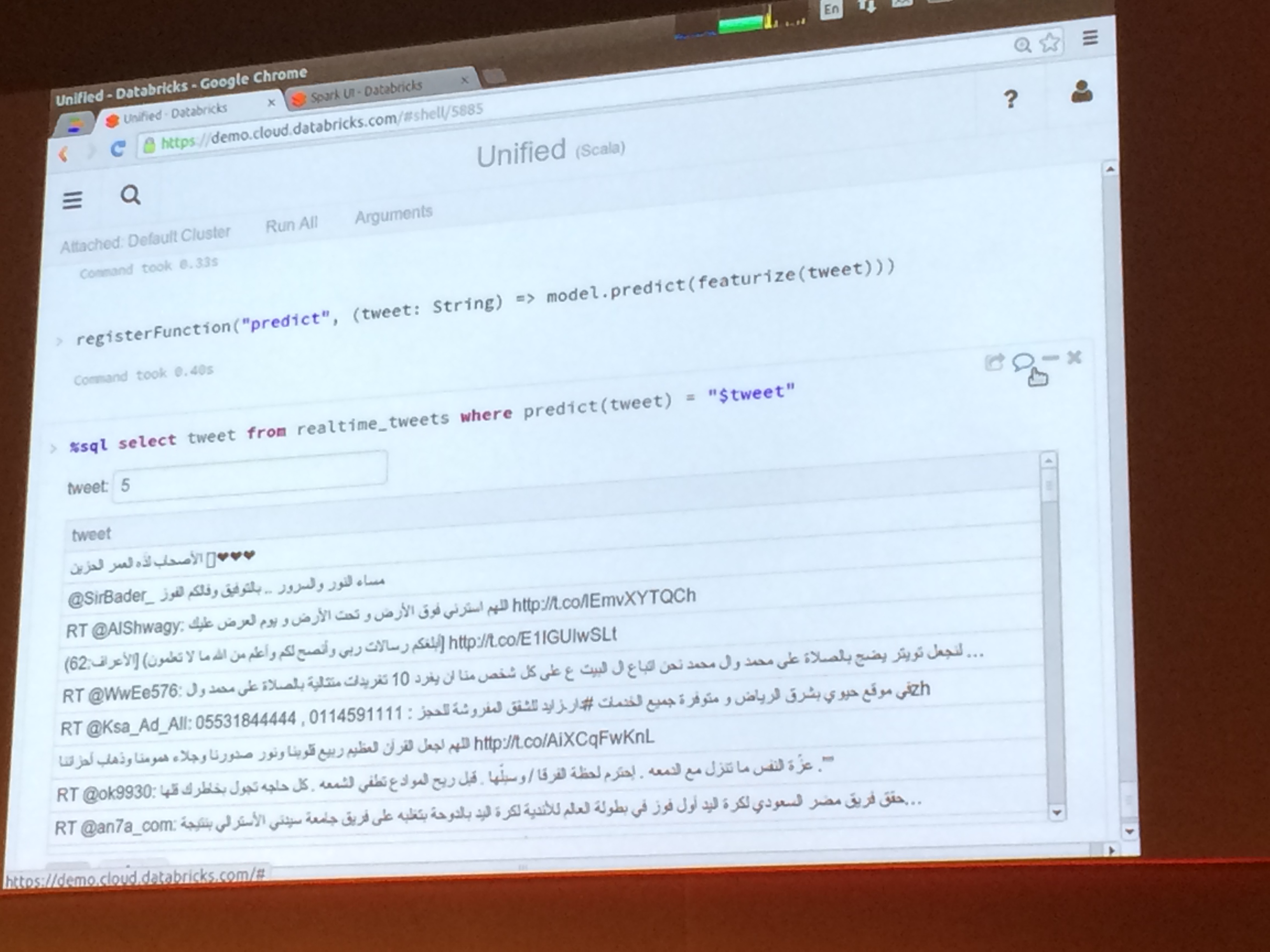
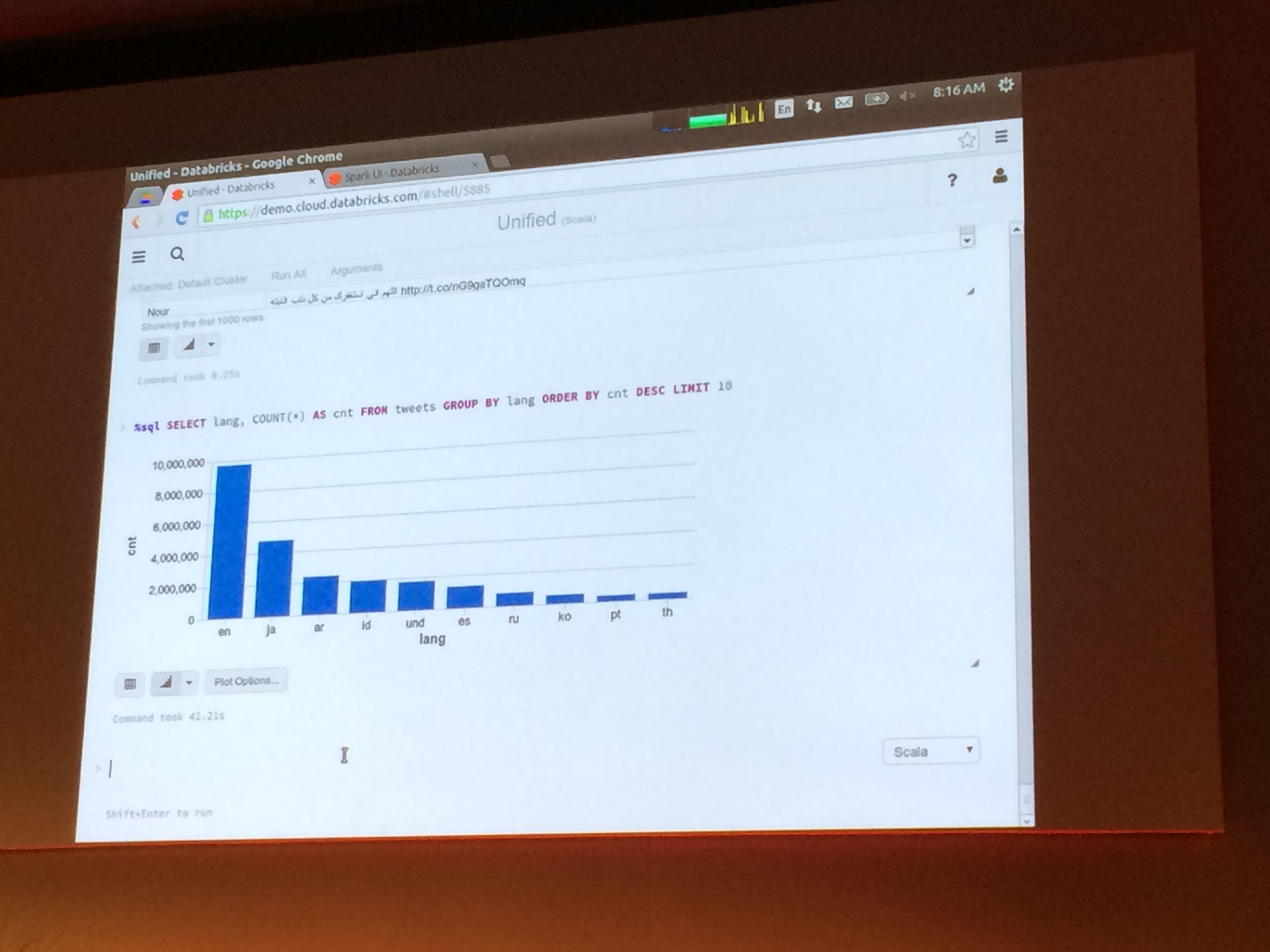
Databricks Cloudを使ってどんどん流れてくるツイートをリアルタイムで言語推定する様子は、
このカンファレンスにおいても会場内にどよめきが起こりました。
Databricks Cloudは2015年2〜3月サービスインを目指して現在絶賛試験中だそうです。
From Raw Data to Analytics with No ETL
Marcel Kornacker (Cloudera, Inc.)
これはすごいです。「No ETL」を謳っています。
Imparaでデータの自動変換を行うという話です。
これもスライドがあがってます。
Predictive Analytics in the Cloud: Predicting Football
Jordan Tigani (Google )
このセッションは何がすごいって、スピーカーがすごいです。
Jordan TiganiさんはGoogleのあのBigQueryの共作者です。
こちらはビデオもスライドも上がっています。
Telling Meaningful Stories With Data
Daniel Waisberg (Google)
Googleのデータ分析主導者でonline-behavior.comの創設者であるDaniel WaisbergさんのKey Note。
Daniel Waisbergさんは行動分析の第一人者ですね。
How Search Can Save Your Hadoop Investment and More
Shay Banon (Elasticsearch)
ElasticSearchの作者、Shay Banonさんのセッションです。


内容的にはApache Sparkのサポートがメインでした。
最後に少しだけ、Elastic{ON}15(ElasticSearch のカンファレンス)の紹介をされていました( ̄ー ̄)
スポンサー・パビリオン
スポンサー・パビリオンには、主催者のCloudera, O’Reillyのブースをはじめ、DatabricksやElastic Search、RedHatなどのおなじみの企業が並んでいました。

企業ブースにはスピーカーが現れることもあります。
※上の写真はAaron Davidsonさん。
ネームホルダーを見せるとTシャツなどのプライズをもらえます。

ちなみにRedHatは赤い帽子がプライズでしたw

O’Reillyのブースでは、O’Reilly本の著者のサイン会が行われました。
著者にサインをいただける上、本もただで貰えてしまいますΣ(゚∀゚ノ)ノ
2〜3日まとめ
カンファレンスを通して印象的だったのは、とにかくもう、
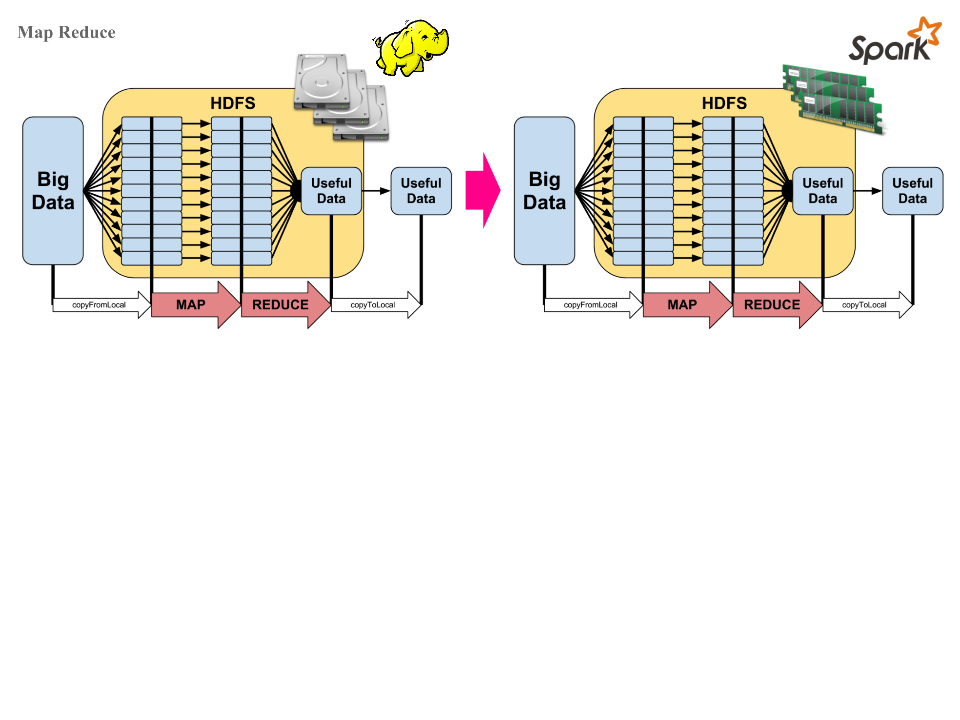
Apache Spark一択だよね
という空気感でした。
メインスポンサーがClouderaだったからかもしれませんが。。。
DatabricksのHossein Falakiさんがセッションの中で述べていた、Hadoopを超えていくSparkに尽きると思いました。