この記事はApache Spark Advent Calendar 2015 22日目の記事です。
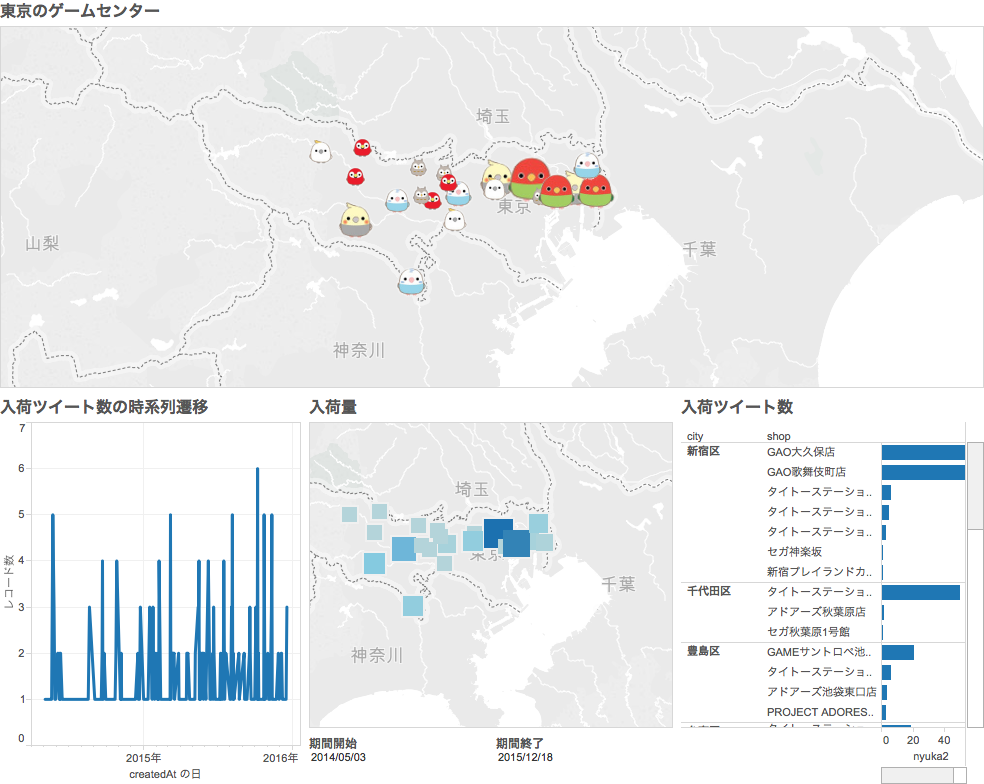
完成したTableauダッシュボード。
ことり隊というのはこれ↓のことです。


ゲームセンターにあるUFOキャッチャーのプライズです。
ゲームセンターにもいろいろ特徴がありまして、ことり隊が置いてあるゲームセンターとそうでないゲームセンターがあります。
ゲームセンターをしらみつぶしに回ってことり隊を探すのも大変なので、Twitterを利用してことり隊の入荷情報をキャッチすることにしました。
1. ゲームセンターのtwitterアカウント
まずは東京都内のゲームセンターをリストアップしてtwitterアカウントを探します。
ゲームセンターのリストは 全国ゲーセン地図Wikiから取得しました。
ゲームセンターの名前からtwitterアカウントを探しました(※ここは手動(;´∀`)です)。
2. ゲームセンターのツイート取得
各ゲームセンターの過去のツイートを全て取得します。
せっかくSparkアドベントカレンダー用の記事なのでここからは全てApache Zeppelin上で操作を行います。
ツイートの取得にはTwitter4Jを使います。
これはspark-streaming-twitterでも使っているライブラリです。
※Sparkが古いTwitter4Jに依存を持っていて若干大変でした。
%dep
z.addRepo("ATILIKA dependencies").url("http://www.atilika.org/nexus/content/repositories/atilika")
z.load("org.atilika.kuromoji:kuromoji:0.7.7")
z.load("com.databricks:spark-csv_2.10:1.2.0")
z.load("org.twitter4j:twitter4j-core:4.0.4")
import java.util.Date
import java.sql.{Date => SqlDate}
import scala.collection.JavaConverters._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SaveMode}
import twitter4j.{Paging, Query, Status, TwitterFactory, Twitter}
import twitter4j.conf.ConfigurationBuilder
lazy val factory = new TwitterFactory( config.build() )
lazy val twitter = factory.getInstance()
// 途中省略
val perPage = 200
var total = 0
val tweets = tokyoTweets.map { g =>
val user = twitter.showUser( g.screenName)
val twNum = user.getStatusesCount
val maxPage = scala.math.ceil( twNum.toDouble / perPage ).toInt
val tw = retreiveRecursively( twitter, g.twitter, total, maxPage, perPage )
total += maxPage
tw
}
val sum = tweets.foldLeft( Seq.empty[Tweet] ){ ( acc, ss ) =>
acc ++ ss.map { s =>
val user = s.getUser
Tweet(
s.getId,
s.getText,
s.getUser.getId,
s.getUser.getScreenName,
new SqlDate( s.getCreatedAt.getTime )
)
} toSeq
}
sc.parallelize( sum ).toDF.write.format( "json" ).mode( SaveMode.Append ).save( path )
こんな感じで、「ツイートを取得してファイルに保存」を繰り返します。
3. ツイートの選別
取得したツイートには様々なものが含まれていますが私が欲しいのはことり隊に関するものだけなのでSparkの機械学習を使ってツイートの選別を行います。
日本語分かち書き
ツイートはほとんどが日本語なので日本語の分かち書きを行う必要があります。
便利なkuromojiを使ってml.Pipelineにフィットする日本語トークナイザーを作成します。
import java.util.UUID
import scala.collection.JavaConverters._
import org.apache.spark.ml.UnaryTransformer
import org.apache.spark.sql.types.{StringType, ArrayType, DataType}
import org.atilika.kuromoji.Tokenizer
object JapaneseTokenizer {
lazy val tokenizer = Tokenizer.builder().build()
}
class JapaneseTokenizer( override val uid: String ) extends UnaryTransformer[String, Seq[String], JapaneseTokenizer] {
lazy val tokenizer = JapaneseTokenizer.tokenizer
def this() = this( s"stok_${UUID.randomUUID().toString.takeRight(12)}" )
override protected def createTransformFunc: String => Seq[String] = {
tokenizer.tokenize( _ ).asScala.map( t => t.getSurfaceForm )
}
override protected def validateInputType( inputType: DataType ): Unit = {
require(inputType == StringType, s"Input type must be string type but got $inputType.")
}
override protected def outputDataType: DataType = new ArrayType(StringType, false)
}
このJapaneseTokenizerクラスもApache Zeppelinで作成します。
訓練データの読み込みとロジスティック回帰によることり隊ツイート判定
Apache Zeppelinで事前に準備した訓練データをDataFrameに読み込みます。
val training = sqlContext.read.format( "com.databricks.spark.csv" ).option( "header", "true" ).load( path ).select(
$"label" cast DoubleType as "label",
$"text"
)
次に、先ほど作った日本語トークナイザー、ハッシング・トリック、ロジスティック回帰を使ったパイプラインを組み立て、訓練データの学習を行います。
val tokenizer = new JapaneseTokenizer().setInputCol( "text" ).setOutputCol( "words" ) val hashingTF = new HashingTF().setNumFeatures( 1000 ).setInputCol( tokenizer.getOutputCol ).setOutputCol( "features" ) val lr = new LogisticRegression().setMaxIter( 10 ).setRegParam( 0.001 ) val pipeline = new Pipeline().setStages( Array( tokenizer, hashingTF ) ) val model = pipeline.fit( training )
今度は判定したいデータをDataFrameに読み込み、作成したモデルで推定を行います。
val allTweets = sqlContext.read.format( "com.databricks.spark.csv" ).option( "header", "true" ).load( path ) val predict = model.transform( test ) predict.where( $"prediction" === 1.0 ).write.format( "com.databricks.spark.csv" ).option( "header", "true" ).mode( SaveMode.Overwrite ).save( path )
“prediction = 1.0”と判定されたデータのみをことり隊入荷情報として抽出します。
抽出したデータは後ほどTableauでロードするのでCSV形式で保存します。
4. ゲームセンターの位置情報を取得
Tableauにゲームセンターの位置をプロットしたいのですが、Tableauの位置データは15万人以上の市区町村のみです。
see: http://kb.tableau.com/articles/knowledgebase/mapping-basics
よって全ての市区町村の位置を取得するためにGoogle Maps Geocoding APIを使いました。
Google Maps Geocoding API
google-maps-services-java
これもApache Zeppelinから使うことができます。
%dep
z.load("com.databricks:spark-csv_2.10:1.2.0")
z.load("com.google.maps:google-maps-services:0.1.9")
Twitterと同様、Google developer consoleでAPIキーを取得する必要があります。
import scala.collection.JavaConverters._
import com.google.maps.{GeoApiContext, GeocodingApi}
import com.google.maps.model.GeocodingResult
val context = new GeoApiContext().setApiKey( key )
val tokyo = sqlContext.read.format( "com.databricks.spark.csv" ).option( "header", "true" ).load( path )
val tokyoList = tokyo.collectAsList.asScala
import org.apache.spark.sql.Row
val tokyoGeo = tokyoList.map { case Row( id: String, shop: String, twitter: String, prefecture: String, city: String, address1: String, address2: String ) =>
val results = GeocodingApi.geocode(
context,
s"${prefecture} ${city}"
).await()
val loc = results(0).geometry.location
GameCentre(
id.toInt,
shop,
twitter,
prefecture,
city,
address1,
address2,
loc.lat,
loc.lng
)
}
tokyoGeo.toDF.write.format( "com.databricks.spark.csv" ).option( "header", "false" ).mode( org.apache.spark.sql.SaveMode.Overwrite ).save( path )
この位置情報付きのゲームセンター情報もCSV形式で保存します。
5. Tableauでゲームセンター一覧と入荷情報を表示する
ファイルは全てCSVで作成したのであとはTableauに読み込むだけです。
Tableau上で位置情報付きゲームセンターCSVとことり隊ツイートCSVをロードし、screenNameをキーとして外部結合します。
Apache Zeppelin + Sparkは、javaのライブラリがいろいろ使えるので便利です。
可視化以外はApache Zeppelinのノートブック上で完結できましたb
Sparkで分析した結果はいろいろなフォーマットで出力できるので連携が楽です。