Solr4を動かしてみるシリーズの3回目です。
さて、いよいよ全文検索エンジンの肝、インデックスの設定です。
3.1. schema.xml
どんなデータから、どのようなアルゴリズムで全文検索を行うかを定義するのが
schema.xml
です。
coreのインスタンスディレクトリの下のconf内に置いてあります。
※schema.xmlがないとエラーになります^^;
schcma.xmlは大きくわけて、
- typesセクション
データ型及び形態素解析器、フィルターの定義を行う、超重要なセクションです。 - fieldsセクション
データ及び適用するtypeの指定、インデックスを作成するかどうか等を定義するセクションです。 - uniqueKeyセクション
ユニークキーを定義します。
で構成されています。
3.2. 何はともあれ日本語読ませようぜ
全文検索を扱うときほど英語圏の方々をうらやましく思うことはないかもしれません。
いかにうまく日本語解析を行うかが全文検索の成功可否を握っています。
schema.xmlのtypesセクションをつらつらと見ていくと、丁寧にも
text_ja
というフィールドが定義されています。
コメントを読むとKuromojiを形態素解析器として使っていると書いてあります。
また、別途text_cjkという統合漢字向けのフィールドも定義されています。
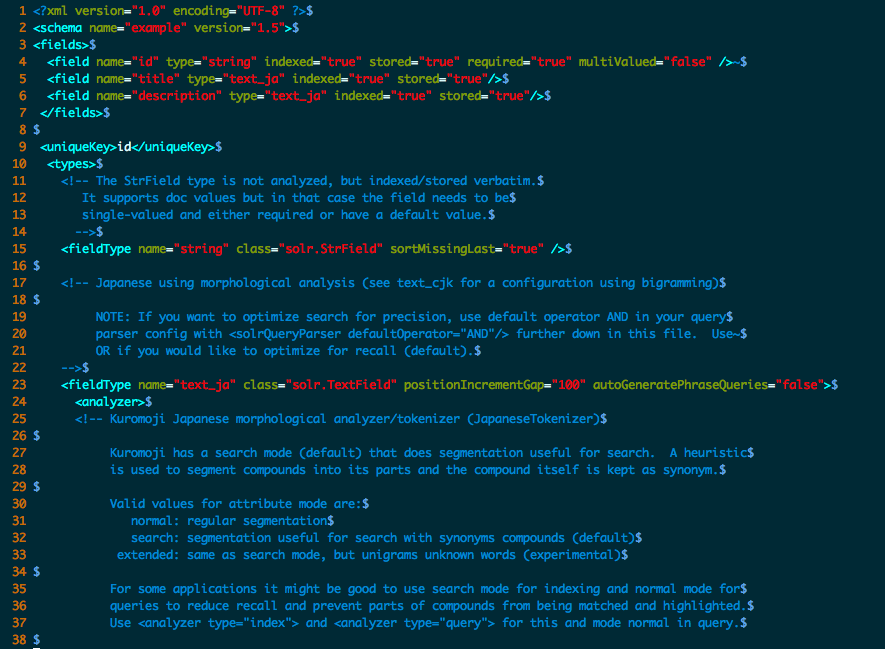
schema.xml
いったん、ユーザ定義辞書や解析器、フィルターの設定はデフォルト値を使うことにして、
データフィールドにこのtext_jaを適用してみます。
fieldsセクションにtitleというフィールドを定義します。
<field name="title" type="text_ja" indexed="true" stored="true"/>
3.3. その他のデータ型
日本語向けのtext_jaの他に、
- デフォルトのintやfloat
- 位置情報を表すlocation
- solr4から導入された新しい位置情報データ型location_rpt
などがあります。
位置情報についてもまた今度書きたいと思います。
補足
schema.xmlから不要なfieldを削除し、solrの再起動を行うと、
ERROR org.apache.solr.core.SolrCore – org.apache.solr.common.SolrException: undefined field text
のようなエラーが出てしまいます。
このログだけをみると、textという名前のtypeを定義してあげたら良さそうですが、そうではありません。
Solr Query – HTTP error 404 undefined field text
非常に紛らわしいのですが、solrconfig.xmlを開くとのや
のにtextという名前のフィールドが使われており、’text’とはこれのことを差しています。
solrconfig.xmlを修正し再起動するとエラーが解消します。