2014年9月11日〜12日にかけて東京ミッドタウンのヤフー株式会社で第5回テキストマイニングシンポジウムが行われていました。
12日(金)の午前中だけ参加してきたので、レポートします。
ニコニコ動画からのポジティブなコメントの抽出
成蹊大の石淵さんの発表です。
ニコニコ動画に投稿されたコメントからポジティブなコメントのみを抜き出す、という研究でした。
ドワンゴと未来検索ブラジルと国立情報学研究所が研究者向けに公開している、ニコニコ動画に投稿されたコメント及びタグのデータを使用したそうです。
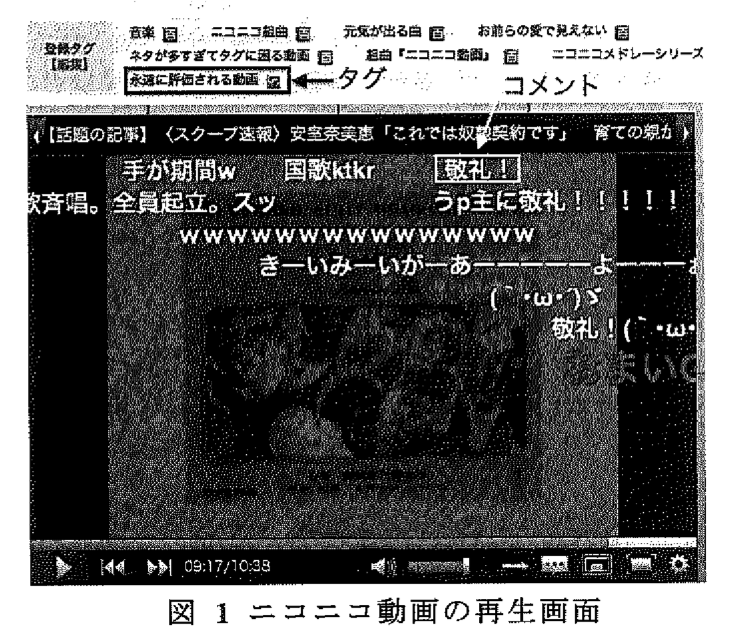
ニコニコ動画に投稿されたコメントと言えば、
「まんせー」や「wwwwww」、「すげええええ!!!」
などの、通常の辞書には載っていない品詞の嵐です。
これらのコメントのうち、どんなコメントをポジティブと判断するか、がこの研究の肝になります。
簡単に手順を述べると、
- ポジティブタグを抽出する(教師データは人力、それを機械学習)
- コメントの正規化(2回以上続くwは2回にまとめる、等 wwwww->ww)
- ポジティブタグが付与された動画においてエントロピー値の高いコメントをポジティブなコメントとする
です。
「コメントの正規化」は一見泥臭い作業ですが、とても参考になりました。
また、岡山大 自然言語処理基礎研究室 竹内研の竹内先生がいらっしゃっていたのですが、
「ニコニコ動画のデータが現代語の辞書に使えそう!」
と喜んでいました。
インターネット通販の商品レビューに基づく有機野菜購入者の特徴抽出
中央農研 竹崎さんの発表です。

自然言語処理及びテキストマイニングに関する発表というよりは、
有機野菜について消費者がどのようなイメージを抱いているか、
また、有機野菜購入者はどのような感想を持つか、という内容だっため、割愛させて頂きます。
価格.comからの有用なレビューの抽出
豊橋技科大 阿部さんの発表でした。
標題のとおり、価格.comから有用なレビューを抽出することがこの研究の目的です。

まず、価格.comに投稿されたレビューには2タイプの書き方が存在することに着目しました。
1タイプ目、項目ごとのレビューの例
【デザイン】
私はこのデザインは気に入ってます。【携帯性】
どこに基準を置くかによりますね。最近のスマートフォンが大型化しているとはいえ、それに比べれば断然大きいです。
同じ7インチ級の他社製に比べれば相当コンパクトですが、何とかズボンのポケットに入るとはいえ、しゃがんだりする事は少し厳しいです。【ボタン操作】
電源ボタンが押し辛い。ここがこの機種の最大の欠点だと私は思います。
2タイプ目、平文のレビューの例
約2年使ったiPhone5から、
バッテリーの持ち、画面の大きさ、
携帯性を求めて
この端末に乗り換えました。
この2タイプのレビュー集合について、
- 項目ごとのレビュー集合
- 平文のレビュー集合
- 項目ごとのレビューと平文のレビューが混ざった集合
と3つの集合をつくり、SVM(liblinear)を使って有用なレビューの自動抽出を行ったそうです。
では有用なレビューをどう判断するか?ですが、
- 価格.comの「参考になった」数 + 発売日からの経過日数/100
- 固有名詞を含む品詞1,2,3-gramをどのくらい含むか
- 文書の長さ
- 改行数
をレイヤーとしてSVMで分類、でした。
「製品名」を名詞ではなく、固有名詞として形態素解析をしたところがポイントだそうです。
特定の品詞が規則的に並んで出現しやすい、を比較レビューの特徴としているのかな。
ヤフージャパンのリアルタイム検索における感情分析
ヤフーの野畑さんの発表です。

ヤフーのリアルタイム検索のバックエンドでセンチメント分析を行っているんだよ、というお話でした。
ヤフーのリアルタイム検索というのは、お恥ずかしながら利用したことがなかったのですが、
facebookに投稿された日本語記事、twitterのツイート(過去1ヶ月)から情報を検索するサービスです。
この発表の感情分析モデルは、とても興味深いものでした。
感情分析モデル
感情分析のモデルとして、下記の2モデルを用いたそうです。
- モデル1: 最大エントロピー法に基づいた複数の分類器を生成して統合
- モデル2: ラベルつきデータと語彙・顔文字シードからラベルなしデータへ情報伝搬する半教師なし学習。
実験に使ったデータは、
リアルタイム検索でトレンディング・ワードとして選ばれた検索語を含むツイートに人手で感情ラベルを付与したもの
です。
素性としては、
- 単語n-gram(1-, 2-)
- 文字(1-3)gram
- 語彙リスト(人手で作成+Webから集めたもの)
- 顔文字リスト(人手で作成+Webから集めたもの)
を用いたそうです。
実験データでの結果としては、
モデル1:
| ポジティブ | ネガティブ | ニュートラル | |
| 再現率 | 0.632 | 0.655 | 0.623 |
| 適合率 | 0.688 | 0.348 | 0.732 |
| F値 | 0.659 | 0.454 | 0.673 |
モデル1の結果をモデル2を用いて修正した場合
| ポジティブ | ネガティブ | ニュートラル | |
| 再現率 | 0.696 | 0.506 | 0.742 |
| 適合率 | 0.712 | 0.484 | 0.740 |
| F値 | 0.704 | 0.495 | 0.741 |
モデル1のみの場合に比べて、モデル1とモデル2を組み合わせた場合では、ネガティブの再現率以外は向上しています。
まとめ
午前の部の最後15分ほど、ディスカッション枠が設けられていました。
もう岡山大 自然言語処理基礎研究室 竹内研の竹内先生に全て持っていかれた感じです^^;
竹内先生は、昨日(9/11木)のNTTデータの招待講演について圧倒されたと語っていらっしゃいました。
よほどすごかったのでしょう。
研究者として、悔しいからメソッドで勝ちたいとおっしゃっていました。
招待講演については、予稿集にも掲載されていなかったので、聞きたかったなと思いました。
まあ、何がすごかったのかと言いますと、
データの入手、分類、ラベリングにおいて、お金をかけて人手で用意し、全て完璧なんだそうです。
なので、(企業と違って十分な資金のない研究室としては)勝負できるのは手法、メソッドの部分なのだと。
そこだけは負けたくないと語っていたのが印象的でした。
個人的にはいろいろとテクニックの部分で参考になることが多かったです。
テキストマイニングシンポジウム、来年もぜひ参加したいと思っています。